另一种常见的评论是大脑的生物设计细节实在是太复杂了,使用非生物技术模拟难以建模和仿真。例如,托马斯·雷写道:
大脑的结构和功能或其组成部分不能分割。循环系统为大脑提供基本生活支持,但它也提供了荷尔蒙,这是大脑化学信息处理必不可少的元素。神经元的膜是一个结构性特点,它确定了神经元的范围和完整性,同时也是沿着这层膜的表面向两极传播信号。这个功能是结构性的,也是生命之本,不能和信息处理分开。17
雷接着描述了几个大脑的“化学交流机制的广阔频谱”。
事实上,所有这些特点可以很容易地进行建模,并且在这方面已经取得很大进展。数学是中间语言。将数学模型转化为等价的非生物机制(比如计算机模拟和使用晶体管的电路),这是一个相对简单的过程。比如说,循环系统释放激素,这是一个带宽非常低的现象,它的建模和复制都不难。某些激素的血液水平以及其他化学影响参数水平可以同时影响许多突触。
托马斯·雷得到一个结论,“一个金属计算系统工作在完全不同的动态属性上,而且永远无法精准地复制大脑功能”。随着神经生物学、脑扫描、神经元相关领域,神经区域建模,神经元电子通信,神经植入物及相关事业的发展,我们发现,我们有能力在任何想要的精确度上复制生物信息处理的突出功能。换言之,复制功能可以“满足”任何想得到的目的或目标,包括图灵测试。另外,有效实现数学模型所需的计算能力远远低于对生物神经元簇建模的理论值。在第4章中,我回顾的一些大脑区域模型(瓦特的听觉区域、小脑等)并证明了这一点。
大脑复杂度。托马斯·雷指出,我们可能很难建立一个相当于“数十亿行代码”的系统,他认为人类大脑大概就在这个复杂度。然而,这个数字是被夸大了的,我们已经知道,创造大脑的基因组仅仅包含大约3千万~1亿字节的独特信息(8亿没有经过压缩的字节,这显然存在大量的冗余),其中大概2/3的内容用于描述大脑的运作。正是因为包含大量随机因素的自组织过程(就像现实世界表现的那样),使得相对少的设计信息扩大到数千万亿字节信息,就像一个成熟的人脑所表现的那样。类似的,在一个非生物实体中创造人类级别智能的任务,不仅是创建一个由无数规则和代码组成的庞大的专家系统,而是一个能学习的、无序的、自组织的系统,一个有生物创造力的系统。
雷继续写道:“有些工程师可能会提出带有球壳状碳分子开关的纳米分子器件,甚至是类DNA的计算机。但我相信他们绝不会想到神经元。与我们开始说的分子相比,神经元的结构大得多得多。”
这仅仅是我自己的观点:人类大脑逆向工程的目的不是要复制消化或其他笨拙的生物神经元过程,而是要了解它们处理信息的关键方式。现在有许多项目都证明了这个观点的可行性。随着其他技术能力的提高,模拟的神经簇的复杂度增加了好几个数量级。
计算机固有的二元论。红木神经科学研究所的神经专家安东尼·贝尔阐明了在我们用计算来建模和模拟大脑上有两个挑战。第一个是:
计算机本身就是一种二元实体,它的物理结构被设计成不会影响到用来执行计算的逻辑结构。根据以往的调查,我们发现,大脑并不是一个二元实体。计算机和程序能分开,但思维和大脑是一个整体。因此大脑不是一个机器,这意味着它不是一个实体化的确定模型(或计算机),因为在模型中,物理实例不影响该模型(或程序)的执行。18
很容易看出这个论点的破绽。计算机能将程序和执行计算的物理实体分离的能力是一种优势,而不是一种限制。首先,我们有专用电路的电子设备,其中“计算机和程序”不再是两个东西,而是一个整体。这种设备不是用编程驱动,而是为特定算法设计的硬件。请注意我不仅仅指在计算机只读存储器中的软件(称为“固件”),这种设备在手机或袖珍型计算机中也能找到。在这样的一个系统中,电子器件和软件仍可被视为二元,即使程序不能轻易地进行修改。
我提到用根本不能进行编程的专有逻辑代替系统,例如用于某些应用程序的特定的集成电路(例如用于图像和信号处理的)。用这种方法执行算法能节约成本,而且许多电子消费产品使用这样的电路。不过虽然可编程计算机需要的成本更高,但是提供了灵活的软件改变和升级。可编程计算机可以模仿任何专用系统的功能,包括我们发现的关于神经元件、神经元、大脑区域的算法(通过大脑逆向工程的努力而实现)。
有人认为逻辑算法和物理设计存在固有联系的系统“不是机器”,这种看法是不对的。如果人们可以理解该系统的工作原理,用数学术语对其建模,然后在另一个系统中创建实例(无论其他系统是不可改变的专用逻辑机器还是可编程计算机软件),那么我们可以认为这是一台机器,当然也是一个实体,其功能可以在机器中重新创建。正如在第4章广泛讨论的,我们完全能从分子间的相互作用开始来发现大脑的运作原理,并对其成功地建模和模拟。
贝尔指出计算机的“物理结构被设计成不干扰它的逻辑结构”,这暗示了大脑并没有这种“限制”。他是正确的,我们的思想确实协助建立大脑,正如我刚才所说,我们可以在大脑动态扫描中观察到这一现象。但我们可以用软件轻易建模和模拟大脑的可塑性,无论是物理方面还是逻辑方面。事实上,电脑软件能和物理实体分开,这是一个架构优势,因为这允许相同的软件应用于不断改善的硬件上。计算机软件就像大脑中的改变电路,也能自我修改,还能升级。
同样的,在软件没有变化时,计算机硬件也可以升级。大脑相对固定的架构才是严重的限制。虽然大脑能够创建新的连接以及神经递质模式,但是其化学信号低于电子100多万倍,适应我们头骨的神经元间连接的数量也有限,也不能升级,除非通过我前面提到的和非生物智能的合并。
层次和循环。贝尔还评论了大脑的复杂性:
分子和生物物理过程控制神经元对传入尖峰的敏感性(包括突触的效率和后突触响应)、神经元产生尖峰的兴奋性、产生的尖峰模式以及新的突触形成的可能(动态布线),这里仅仅列举了4个子神经元层最明显的参考值。除此之外,我们看到,一些跨神经元的作用,比如局部电场、氧化氮的跨膜扩散,分别影响着连贯的神经激励(coherent neural firing)和传递给细胞的能源(血流量),后者直接影响着神经元活动。
还可以继续列举很多例子。我相信,任何人只要认真研究神经调节、离子通道或突触机制,肯定就不会认为神经元层面是一个单独的计算层面,甚至会发现它是一个有用的描述层面。19
虽然贝尔在这里指出,神经元并不是模拟大脑的适当层次,但是他主要想说的和托马斯·雷的论点很相似:大脑比简单的逻辑门复杂。
对此,他作了详细阐述:
有人认为为了描述大脑的功能,一个结构性的水或一个量子一致性是必需的细节,这种观点显然很荒谬。但是,如果在每一个细胞中,分子来源于子分子过程的系统功能,如果一直使用这些过程来遍历大脑,来反映、记录和传播的时空相关性分子的波动,来增强或减弱反应的可能性和特异性,那么这种情况就与逻辑门有着质的不同。
他在某个层面反驳了神经元和神经元间连接的简单模型,这些模型应用于许多神经元项目。大脑区域模拟没有使用这些简单模型,而是使用基于逆向工程结果的逼真数学模型。
贝尔真正的观点是:大脑是非常复杂的,还有很多后继反应,因此大脑是难以理解的,也很难对其建模和模拟其功能。在贝尔看来,主要问题是,他不能解释大脑设计的自组织、无秩序、不规则特性。可以肯定的是,大脑非常复杂,但是很多情况下只是看起来复杂而已。换言之,对大脑的设计原则比表面看起来的要简单些。
为了理解这一点,我们首先考虑大脑组织的不规则性质,这在第2章讨论过。在创建一个模式或设计时,分形是一个迭代使用的规则。该规则通常很简单,但由于迭代使得设计显得很复杂。一个著名的例子是由数学家伯诺伊特·曼德尔布罗设计的Mandelbrot set。20 Mandelbrot set的可视化图片非常复杂,在复杂的设计中嵌套复杂的设计。当我们看Mandelbrot set的一个图像时,随着看的细节越来越细,但复杂度却永远不会消失,我们可以看到一个同样的复杂度。然而关于所有复杂度的公式却是惊人的简单:Mandelbrot set用一个简单的公式来描述,这个公式是Z=Z2+C,Z是复数,C是常量。公式是迭代使用的,图9-1所示的曲线图描述了结果的二维点。
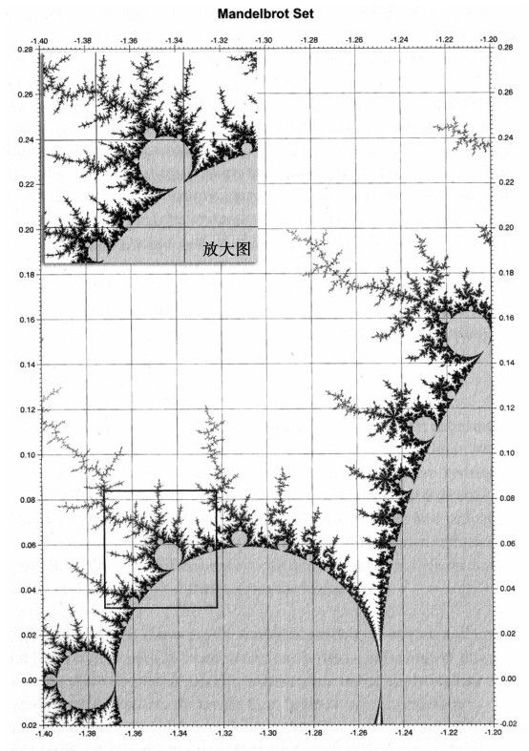
图 9-1
关键点在于,一个简单的设计规则就可以创建巨大的复杂度。史蒂芬·沃尔夫勒姆表达了相似的观点(见第2章),他在细胞机器人上使用的规则也很简单。这种见解抓住了大脑设计的真谛。我曾经说过,经过压缩的基因组只是一种相对紧凑的设计,甚至比当代的一些软件程序还小。但是正如贝尔所指出的,大脑的实际实现却要复杂得多。就像Mandelbrot set一样,当越来越精细地观察大脑的特征时,我们仍然能够很清晰地看到每个层次的复杂度。从宏观的层面来看,连接的模式看起来很复杂;从微观的层面看,一个神经元单个部分的设计(比如树状突)也同样复杂。我提到过,如果想描述一个人大脑的状态,我们至少需要万亿字节的信息;但是如果只是设计大脑,那么只需要千万字节的信息。因此,大脑所表现出来的复杂度与设计它所需的信息的比率至少是10 8:1。虽然大脑信息的开始阶段充满大量的随机信息,但随着大脑与环境发生复杂的相互作用(人的学习和成熟),这些信息才变得有意义。
实际设计中的复杂度是由设计阶段的压缩信息(基因组和支持分子)所决定的,而不是由迭代使用设计规则所创建的模式来决定的。我认为,虽然基因组中约有3千万~1亿字节(当然比Mandelbrot set中定义的6个字符复杂得多),但这并不代表它是一个简单的设计。不过这个复杂度我们能够通过技术来管理。很多观察家被大脑物理实体表现出来的复杂度所迷惑,他们没有认识到,设计的不规则特性意味着实际的设计信息远比我们从大脑中看到的信息简单。
我在第2章中也提到,基因组的设计信息有一种随机的不规则性,这意味着当每一次迭代规则时,都存在着一定的随机性。也就是说,例如,只有很少的基因组信息用于描述小脑(cerebellum)的布线图,而小脑包含了大脑中半数以上的神经元。很小一部分基因用于描述小脑中4核细胞的基本模式,而且从本质上说,“重复这种模式几十亿次,在每个重复过程中都存在一些随机的变化”。结果看起来非常复杂,但所需的设计信息其实相对较少。
试图将大脑设计与传统的计算机相比较将是一个令人沮丧的行为,在这点上,贝尔的判断是正确的。大脑并不是那种典型的自上而下(模块)的设计模式。它利用随机的不规则的组织结构创建一个无序的进程,这是一个没有可预见性的进程。若一个成功的数学模型用于模拟与仿真无序系统,用于了解诸如天气和金融市场等现象,这个模型同样也适用于大脑。
贝尔没有提到这种方法。他认为,大脑与传统的逻辑门和传统的软件设计相比有着巨大的差异,因此他得到了一个没有经过充分论证的结论,即大脑不是机器,也就不能用机器去模拟它。尽管他说得很对,标准逻辑门和传统模块化软件的组织并不是分析大脑的恰当方法,但这并不意味着我们无法在计算机上模拟大脑。因为我们可以用数学术语来描述大脑的运行原则,而我们又可以在计算机上对任何一个数学过程建模(包括无序过程),所以我们能够实现这种模拟。而且事实上,这些工作一直在做,并且一直在进步中。
尽管贝尔持有怀疑态度,但是他对于我们将更好地理解我们的生理和大脑,并对它们加以改进的观点,表达了一种谨慎的信心。他写道:“会不会出现一个超人类的年龄?为了这个目标,要有一个强大的生物先例出现在生物进化主要的两步中。第一,真核与原核细菌的共生;第二,在真核生物中出现多细胞生命形式……我相信,一些不可思议的事情(像超人类的寿命)也许会发生。”