一般来说,对社会影响的社会心理学研究运用相关法(correlational method)或者实验法(experimental method),后一种方法运用得更为广泛一些。本附录在简述相关法后,将着重论述实验法。
现场研究中的相关法
在心理学中,所有的研究都包含了对行为的观察。一些研究,即所谓的现场研究,对自然而然存在的现象或者变量运作进行观察。换句话说,研究者力图对现象或事物的“本来面目”进行系统的、相对客观的和无偏差的观察。研究者不会妨碍它们的运作,或试图改变或控制任何变量。研究者的任务只是确定两个或者更多变量间是否存在相关[1],以及有何种程度的相关。例如,一项现场研究的研究者揭示,位于佛蒙特州本宁顿学院的女大学生在大学4年时间内,其政治态度与社会态度逐渐变得更加的宽容(Newcomb, 1961)。另一项研究表明,对于小学生来说,如果他们的父母具有非权威人格并采用非惩罚性的抚养习惯,随着学校废除种族歧视,这些小学生的种族偏见也会降低。然而,当父母具有权威人格并采用惩罚性的抚养习惯,他们的孩子则没有出现种族偏见的降低(Stephan&Rosenfield, 1978)。
这种现场研究,以及其他使用调查法和民意测验所进行的研究,对于发现和分析行为关系,对于指出在这些关系中可能发挥了重要作用的变量,有十分重要的价值。因为观察是在日常生活中进行的,只有最小限度的干预,因此这种观察对日常生活中的应用价值可能高于那些在有更多人为限制的实验室中进行的观察。然而,大多数的现场研究是相关性的。变量仅仅被观察,并没有受到控制或者改变。两个事件或者行为(A与B)可能有很强的关联性,或者相关;然而如果仅仅只是观察它们,那么我们无法确定究竟发生的是以下何种情况:是A导致了B,还是B导致了A;这种关系是否只是一种巧合;也许一个因素经由一个中间变量(未知的变量)的运作间接导致了另一个因素;还是第三个变量既导致了A又导致了B。
例如,关于婚姻关系的研究有时会报告,幸福的夫妻比不幸福的夫妻有更多的性生活。那么是性导致了幸福,还是幸福导致了性?两种因果关系都有可能,但是仅仅通过观察到的性与幸福婚姻的共变,我们无法确定因果关系。我们同样无法确定是否有第三个变量导致了这一关系。可能一些夫妻繁忙的工作导致他们大多数时间都处于分离状态,而这种分离状态既可作为不幸福的根源,又可成为性生活的一个明显障碍。
通过改变测量变量的时间,有时相关研究能够就因果关系提供较强的(但仍然不是确定的)理解。观察可能发现A在时间1所发生的改变与B在时间2所发生的改变有相关,而B在时间1所发生的改变与A在时间2所发生的改变几乎没有关系。这一模式暗示A对B有因果性的影响。当然,使用某些统计程序可能也能够获得关于因果关系的提示。
实验作为因果关系的信息源
为了获得真实的因果关系,你需要做实验。实际上,绝大多数社会心理学研究是实验研究。实验的关键就是控制。实验者对假定的原因变量进行控制,称其为自变量(independent variable)。他操纵自变量,将变量的一种水平、数量或者类型指派给一种处理条件下的被试,将另一种水平、数量或者类型指派给另一条件下的被试,等等。同时,对于那些可能对被试产生影响但是却与需要验证的假设无关的其他变量,实验者则力图使其保持恒定。
实验者通过将被试随机分配到不同处理条件中,从而对变量进行进一步地控制。这其中包括使用一些随机方法(例如,掷硬币或者参考由计算机生成的随机数据表)来决定每个被试接受怎样的处理条件。因为处理条件的分配完全基于偶然性,所以接受不同水平自变量的被试在他们曝光于自变量前不太会存在着任何系统差异。随机分配通常保证了那些使人们存在差异的多种因素在不同处理条件之间是平均分布的。
在引入了假定的原因变量——自变量——之后,对被假定为结果的被试行为[被称为因变量(dependent variable)]进行观察。如果接受了不同水平自变量的被试在因变量上表现有所不同,那么根据实验控制的逻辑,自变量必然就是原因。其他所有的变量都是恒定的,而在测量因变量以前对自变量进行了操纵。
因此,你可以发现实验者不是等着行为自然地发生,而是创设出他认为能够诱发行为发生的条件。在这个意义上,实验者是创设出了一种人为的环境或说干涉了自然过程。而他们这样做是为了:(1)在已知条件下使事件发生,而这一已知条件随后能够被单独地重复;(2)在实验者对准确观察做好准备时,使因变量产生;(3)有可能确定自变量对因变量产生影响的趋势和大小;(4)消除了因变量与自变量间的关系源于两者直接因果联系之外的其他因素的可能性(例如,Y既导致了A又导致了B)。
实验始于3个基本决策。在可被许多被试觉察到而且可以从不同维度进行各种水平的反应的大量刺激中,实验者选出一个特定的刺激,有机体(即被试),以及反应模式。可将实验看作由三个互相有重叠的圆环构成,它们分别代表:(1)刺激(自变量);(2)被试;(3)反应(因变量)。这三者与正在研究的总体问题有关。通常,研究者研究的只是它们交集中很小的一块或一点。例如,在关于说服信息的理解对态度改变的影响的研究中,自变量可能就是伴随录音信息的4种大小的静态噪音,从不会造成干扰的微量噪音到会造成大量信息难以被理解的巨大噪音。被试是在一所指定的大学选修心理学导论的60名大学生。而因变量则是在10点量表上对信息结论的赞同度的评分。
根据理论意义上的区别,把所有刺激分别划分进了不同的范畴中。例如,20世纪50年代和60年代在耶鲁大学沟通研究项目所进行的说服研究中(见第4章),根据沟通是双向还是单向,是否会唤起恐惧,明确还是含蓄地陈述其结论等等,对所有的沟通进行了分类。当按照这样的方式对刺激进行分类时,实验者有意识地决定忽略刺激的某些方面,而强调刺激的另一些方面。例如,信息中语句的长度乃至信息的主题可能会是无关的。这意味着实验者从有明确结论的、单向的、能够唤起恐惧的这一大类沟通中选择刺激。他所选择的特定沟通可能或多或少地频繁使用到了长度为25个单词的语句,并且可能是关于枪支控制而不是关于生育控制的。研究者期望,在所有这些不相关的特征上能够获得相同的结果(即,内容、长度、句法等等不会改变所考察的基本关系)。
实验者对被试类型和反应类型的选择存在共同点。以大学生(或者可能是工人)为研究对象以期发现“一般人”情况的研究者,通常假设不同群体间的许多差异不会影响研究中所建立起来的基本因果关系。例如,许多关于从众的研究(见第2章)以大学生为研究对象。当研究者感兴趣于拥有一致意见的多数派的人数(例如,一个,两个或者三个人)是如何影响被试对多数派意见的依从频率,那么,平均而言,大学生相对其他成年人是“独立思考者”的程度可能与问题无关。无论某个特定被试团体的总体从众水平如何,多数派人数与从众之间的关系应该是不变的。与此相似,无论是以按压按钮还是以点头赞同来表示从众的反应,也应该与问题无关。
当然,如果有理由相信,对于不同教育水平、社会地位、年龄、性别或其他特质的人而言,基本关系会有所不同,那么应该进行额外的研究以对不同类别的人进行比较。
如果实验者能够从广泛的变量和被试中选择大量的特定案例,那么关于选择哪些案例的决策常常基于便利性、易得性和测量准确性以及可控制的程度。因此,自然就产生了两个问题:(1)所选案例确实能够以这样的方式被测量吗,即无论谁来进行测量或何时进行测量都能得到相同的结果吗?(2)所选择的案例是否准确地反映了研究者感兴趣的过程变量或者概念变量?第一个问题关注于信度(reliability),而第二个则关注于效度(validity)。
信度可等同于一致性或稳定性。在其他所有条件都相等的情况下,所选择的反应测量是否能在重复中得到相同的结果呢?而在十分相似的测量条件下是否会得到相同的结果呢?
效度是一个更难论证的复杂问题,它有许多涵义,我们在此只涉及其中2个。概念效度(conceptual validity)指实验者进行的处理、观察和测量是适当的,具体地代表了实验者真正想要了解的一般抽象类别。态度研究者感兴趣的是态度,而不是10点量表上的评分。在理论上,研究者希望得到的是一系列特定操作,这些特定操作能够将抽象概念锚定于真实世界中的事件,但同时这些操作应该是尽可能纯粹地作为抽象概念的例证。
测量的效度同样可由另一种方式来思考,我们称之为内容效度(content validity)。因变量分数上的任何变异都有两个成分:真实变异和误差变异。随着测量分数更加接近(假定的)真实分数,测量也就变得更加有效。因为测量分数的变异不止受到了所研究的相关反应中的变异的影响,还同样受到无关误差源的影响,因此测量丧失了它作为潜在真实反映系统的有效代表的地位。系统误差使测量得分在特定方向上存在偏差,而随机误差则导致测量得分在任何方向上偏离真实值。
例如,当实验者无意识地把其所期望的反应通过一些线索传递给被试时,或者当实验者知道某个被试接受了某个特殊处理(例如药物)因而影响到他对被试的行为进行客观评价时,可能就会出现系统误差。而随机误差则源于环境的干扰或者方法上的不足。一个瞬时事件可能会改变对任何在特定条件中所操纵刺激(例如,当在一个条件化程序中出现了一个意外的噪音)的反应。相似地,当实验者以不同方式把刺激呈现给相同处理条件下的每个被试,那么测量分数可能会以无规律和未知方式增加或减小。通过使用控制程序、客观的评分方法、随机化和控制组能够减小系统误差。随机误差的消除主要依赖于标准化的方法学,以及利用那些不会使被试反应随机变化的环境。
根据现在重新界定的研究目的,我们可能会认为实验就是一整套客观的程序,目的是为了从背景噪音中分离出信号。真实分数,或信号,可能会从概念上得到净化以与其他相似的信号相区别。处理程序旨在放大信号,而测量程序应该能够探测到哪怕十分微弱的信号。要做到这两点,必须对竞争性的信号和背景噪音进行适当的控制,可以通过两种方法来进行控制:使二者最小化,以及就二者对主要信号的观测值的贡献进行准确评价。
但是,对实验结果的概化又是怎样的呢?几乎没有科学家会满足于把研究结论局限于特定的刺激与操作以及特定样本所做出的特殊反应。我们希望研究结论能够处在一个更高的抽象水平上。我们知道,当研究基本的心理过程时,研究者可能会假设他们的结果能够放在更大总体的“大背景”中。但是,在实验研究中有许多因素与确保这一假设的合理性有关。我们将在下面这一节中对这些因素进行探讨。
实验的概化:统计推论
对一项研究的结果进行推论时常会存在风险,即使研究设计精巧并且被认真地实施。然而,通过客观的统计方法对由一套特殊观测得出的特定结论发生错误的可能性进行评价,可以估算出这种风险的范围。假设我们希望评价人们是否通过小组讨论改变了他们对毒品使用的态度。我们可能分别在讨论前和讨论后对参与者的观点进行测量。首先,通过某些描述统计以方便有效的方式对被试样本的观点评定进行总结。通过计算平均数、中位数或者众数可以回答“讨论前后典型得分或者平均得分是多少”这一问题。而通过反应的变异性(全距、或标准偏差)能够回答“单个被试相对这一代表值发生了多大偏离”。
然而,为了确定小组讨论是否朝所提倡的方向改变了态度,有必要将所获得的描述统计结果与在没有小组讨论、仅仅对观点评定的重复测量情况下发生的改变进行对比。把测量分数的分布与不同类型的理论分布进行对比,使我们可以估计出数据不是源于偶然性而是源于一个统计上可信赖关系的可能性(推论统计)。对处理变量的不同行为(在最初可比较的被试组之间)可能是一个更加“真实的”差异,这一差异可能源于3种因素的直接作用:观察的数量,差异的大小以及反应的变异性。随着观察次数(N)的增加,随着不同组之间表现(通过某种描述统计来测量)的差异增加,以及随着每个单组内的变异减少,所获得的差异倾向于更为显著。
在心理学中,显著性(significance)的概念被定义为确定一个特定结果是源于处理的效果而不是观察中的随机波动(误差变异)的最小标准。置信度水平(probability level),任意设定为p〈.05(p小于0.05,或者5%),就是这个最小标准。这意味着所发现的差异在100次中可能仅仅只有5次是因为偶然性造成的。因此,我们可以推断,在100次实验中有95次,差异不能归结于偶然性,而这次的结果是属于95次的范畴。在某些条件下,研究者可能需要一个更加严格的拒绝概率,例如p〈.01或者甚至p〈0.001(即,实验者因把所获得差异作为一个真实差异而得出错误结论的可能性,只有千分之一)。
虽然通过使用概率的语言而非绝对的语言对结论进行表述,降低了结果推论的风险,但是对观察到的行为样本按照两种方向中的任一种进行推论时都有可能包含了相当的风险。人们可能将推论上升至一个更加抽象、概念水平的解释上,也可能下降至一个更加具体、特殊的案例上。在前一种情形下,外推中可能产生误差,因为特殊的结果无法揭示假定的一般关系或者理论过程。在后一种情形中,一般关系能够预测某个特定个体的行为这一假设本身可能有问题。
在上述两种情形的每一种中,都可能存在着两种类型的错误。如果所获得差异的显著性是p〈0.05,那么实验者在得出结论认为他发现了一个真实的效应时,每100次中会有5次犯错。这是因为单凭偶然性本身就能够造成那样大小的差异,而一个特殊实验可能刚好代表了5次偶然性中的一次。于是我们有了Ⅰ型(或称为α)错误:当关系实际并不存在时推断关系存在。让我们以一个不同的视角看看概率和决策过程,假设因差异显著性处于0.06的概率水平(超出了科学可接受的惯有限度)而拒绝了差异显著的结论。那么当关系存在时,相反地调查者在100次中会有94次下结论认为关系不存在。这就是Ⅱ型(或称β)错误。
心理学家如何决定是更加冒险(Ⅰ型错误)还是更加保守(Ⅱ型错误)呢?无疑,他的策略应该经由以下几点来决定:每种类型结论的行为意义,每种错误类型的相对代价或风险,以及每种错误类型对创造性思维的激励或抑制作用。例如,在通过向上推论形成关于物理现实或心理现实的概念化、理论化的陈述时,Ⅱ型错误(它可能会导致过早地封闭了调查研究的领域)对进展造成的损害可能会高于Ⅰ型错误(该错误应该会比较容易地在他人的独立重复研究中发现)。然而,如果没有什么重复性的研究,那么I型错误可能会一直存在,从而导致了在测量无根据的原有假设的相关衍生物上白费劲。
从实验室推广至真实世界
实验主义者所面临的困境就是获得控制的同时又丧失了效力。心理变量的全距以及强度无法在实验室背景中获得。这是因为在一个实验中,自变量呈现的时间相当的短。同时,被试的任务常常与他其他的生活经验只有有限的关联,并且在他未来的活动中也只有非常小的应用。此外,实验操纵的性质和强度常常受到法律、伦理与道德考虑的限制。虽然变量的效力在一个无控制的自然环境中常常能够得到最好证明,但是在这一水平上对现象进行研究可能存在以下风险:丧失对其中相应过程的理解,缺乏对因果关系的详述以及无法将复杂的因素网络分解为相应的成分变量。另一方面,由控制精巧的实验所获得的收益可能会被实验的琐碎内容相抵消。通过提纯、标准化、控制以及选择特定的刺激、反应维度,实验者可能对他意欲研究的现象或者问题创设了一个有所差距、打了折扣的版本。此种条件下得出的研究结果可能几乎没有任何的实际意义。
通过研究策略的结合使用以及在同一主题上进行多种不同实验,可以在任何特定的研究中克服这些局限性。例如,假设实验者担心在一个诱发依从的认知不协调实验中,使用金钱奖励来改变的“合理化”可能与通过向被试提供关于依从的社会原因而改变的“合理化”有所不同。那么他可以通过在实验中引入对“合理化”的概念验证或者运用许多不同的实验来系统化地复现被研究的概念变量,从而对上述可能性进行评估。
实验真实与生活真实。为了填补实验室与现实之间的这条鸿沟,实验研究者们通常力图使他们的实验真实。最为重要的一类真实就是实验真实(experimental realism),实验真实在本质上是指“使实验生活化”(Aronson&Carlsmith, 1968;Aronson et al., 1990)。实验务必要使其研究程序对被试有吸引力,使被试能够投入到实验中,同时要使自变量能够引起被试的注意并且维持注意。被试应被自己在实验室中的经历所吸引,对所发生的事件(自然地)做出反应而不是感到讨厌,考虑(或许担忧)把他们自己视作被仔细审查的对象,或者试图分辨出实验者的理论是什么。如果一个实验不具有实验的真实性,那么就有一种风险,即所观察到的因果关系可能仅局限于当人们知道自己处于一个实验中时。由此,我们通常几乎不可能了解任何的一般心理过程。
在一些情形中,实验者同样会追求生活真实(mundane realism),生活真实是指以变量在日常生活中存在的方式对变量进行处理和测量(Aronson&Carlsmith,1968)。对提问方式如何影响到目击者对犯罪事件的记忆特别感兴趣的研究者(见第8章),会让被试观看一起现场表演的犯罪活动,然后让他们在不同类型的提问条件下报告自己的记忆。相对于让被试观看一系列的幻灯片然后对他们进行提问,这种方式可能更加具有生活真实性。当寻求把实验结果推广至日常生活中的某个特定背景或是心理过程,而不是推广至一个更为广泛的背景或是过程时,生活真实性就尤其重要。
实验效度。我们已经知道,因变量必须有效。从总体上说,效度的概念同样适用于实验,并且这个概念极好地总结了我们在讨论实验时所关注的主要问题。我们从实验中得出的结论无效——并因此而无法推广——的方式可能有两种。我们可能错误地下结论,认为在所使用的特定处理与特定测量之间存在因果关系,而实际上观察到的关系是源于某个其他的因素,一个人为的结果,或者混淆变量(confounding variable)。在这样的情形下,我们可能会就实验的内在效度(internal validity)得出一个错误结论。此外,还可能是错误得出结论,认为一个特定的因果关系(同样)适用于未在研究中进行评估的概念变量的所有其他实例;即,这一因果关系被推广至其他的人、背景、测量和在概念上等价的处理。在第二种情形下,实验的外部效度(external validity)是关键。为了避免得出这两类无效结论,一种方法就是觉察到导致实验研究中效度缺失的更为普遍的根源,然后考察实验设计的不同方面从而克服每种缺陷。
让我们首先考虑一下内部效度缺失的一些可能根源[2]。
1.内在的人为问题(internal artifact):实验者不愿发生的一个未受控制事件可能导致了实验者所观察到的结果。如果发生了这样的情况,那么特定自变量引发特定效果的这一结论可能就是不正确的。
2.被试的改变(subject change):刺激事件(自变量)可能发生于被试内部,而不是发生在他的外部。例如,被试可能对个人问题感到厌恶或者担忧。
3.测验的敏感性(testing sensitization):被试对第2个测验(后测)的反应,可能会受到初始测验(前测)的影响。
4.被试选择的偏差(subject selection biases):如果不同实验组的被试不是随机分配的话,那么实验组间的差异总有可能并非是由自变量的差异引发,而是由不同组之间先前就存在的差异所引发。
5.耗损(attrition):如果在将被试随机分配到不同实验条件中以后,一个无法控制的因素导致在最后结果分析中剔除了一些被试,那么就无法得出关于自变量对因变量的影响的有效结论。一种无法控制的因素可能就是被试选择不再继续进行实验。另一种因素则可能源于实验本身的一些特征。
在理解外部效度——或推广至其他人、背景等等——的来源之前,我们必须对交互作用(interaction)的概念加以讨论。假设我们关注于替代性强化大小对模仿的影响(见第2章),那么为了研究这一问题,我们可以向一些年幼儿童呈现一部关于成年男子殴打充气塑料娃娃的影片。影片中作为榜样的男子在殴打塑料娃娃后,得到了0个、1个、2个、4个或者10个棒棒糖。随后给儿童与充气塑料娃娃玩耍的机会,而研究者则记录了儿童做出与榜样相同的“攻击性”行为的频率。假设模仿反应的平均数量随着榜样接受到的奖励大小的增加而增加。那么,研究者可以下结论,替代性强化数量的增加导致了人们更多的模仿。
请注意以上结论并没有受到限定。这暗示着替代性奖励的数量与模仿数量间的这种关系适用于所有类型的榜样、被试、奖励、反应、背景以及用来呈现榜样行为的媒体。这一结论并没有说,这一关系只适用于来自于一个特定学校的特定年龄群体的儿童,他们观看了在电影中一个特别的男性榜样对一个充气塑料娃娃施以某些特定行为后,得到了棒棒糖。如果一名女性榜样殴打充气塑料娃娃,那会是不同的关系吗?让我们假设,随着对女性榜样奖赏的增加,模仿数量却有所减少。如果自变量(替代性强化的数量)与因变量(模仿的数量)之间的关系因其他某个变量(在这个例子中,榜样的性别)的作用而发生了改变,那么可以认为两个变量发生了交互作用从而共同决定了结果。
交互作用可以有许多类型。模仿的总量在两种榜样中可能都有增加,但是以不同的速率。或者,这种关系也可能会有逆转(一个增加,另一个减少)。这种关系甚至有可能只在一种条件中存在,在另一种条件中却没有出现(替代性强化的数量完全没有效果)。简言之,交互作用的出现,限定了研究者感兴趣的结果或关系能够在跨情境、跨背景、跨被试等方面进行推广的范围。在对社会影响和态度改变的研究中,很少发现有不受与其他变量的交互作用所限制的变量。研究者事实上常常专门设计某种研究以期发现交互作用,因为交互作用向我们提供了关于某种因果关系什么时候存在而什么时候不会存在这一至关重要的信息。
现在我们可以来考察一下可能限制了外部效度的一些更加普遍的因素。
1.测量的反应效应(Reactive effects of measurement):当对被试进行一个测验,假定是自陈式态度量表,那么进行测量本身可能就会对被试如何做出行为产生影响。在态度测量的研究中,测验可能变成诱发态度的刺激条件;被试以前可能并没有这一态度,或者在意识到测验或实验的意图以后改变了他的真实反应。因此,任何结论都只限于了进行过测验的被试。
2.选择偏差与实验变量的交互作用(interaction of selection bias and experimental variable):实验变量的效果可能只有在某类被试身上才会显现。例如,如果研究只选择了具有极端态度的被试,那么通常会对那些更加温和被试的态度产生影响的变量,可能就不会对这些极端的被试产生影响。
3.实验的反应效应(Reactive effects of experiment):实验背景中与实验背景外之间的一些特殊差异,可能对决定实验结果是否具有应用价值至关重要。例如,在实验中被试可能总是非常积极地参与到沟通中,而这一情况在自然情景中可能不会发生。
4.多重处理效应(multiple treatment effects):有时,每个被试可能在呈现和不呈现实验变量的情况下均接受测量。因此可能会产生顺序效应;即,第一个处理会影响到被试对第二个处理的行为反应方式。因此,结果可能仅适用于那些接受了不止一种处理的被试,并且可能仅适用一种处理的顺序。
实验设计
既然我们已经知道内部效度缺失和外部效度缺失的一些更为普遍的根源,那么让我们来看看如何能够通过不同的实验设计来消除这些误差来源。
表A.1以总结的形式呈现了5个十分复杂的实验设计。表格中的符号○代表观察或测量,而符号M则代表对在那种条件中所呈现自变量的一个实验处理。在每个这样的实验中,至少有两组被试。一些被试接受处理;另一些被试则不接受处理,这是随机决定的。通过每一被试组前面的符号R来表示被试被随机地分配到不同条件中。例如,表A.1中呈现的最简单的设计是一个双组设计,在此,被试被随机分配到两个组中的任一个。只有组1中的被试接受处理,随后对两组都进行观察。
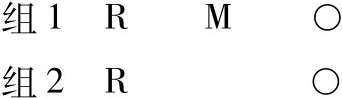
同样,在表中列出了先前已描述过的导致外部效度缺乏的各种根源。对于每种设计,如果在与效度缺乏的特定根源相对应的那一栏中标注了“是”,就意味着这类实验设计无法消除那个特定类型的误差。“否”则表示不存在这个问题。(效度缺乏的内部根源没有在表中呈现。只要研究者恰当地设计和监控实验程序,那么对于这些设计来说导致效度缺乏的那些内部根源都不会成问题。)
使效度缺乏的根源最小化的“最好”设计就是不同样本前后测设计。这里,实验者随机将被试分配至许多条件中。在处理以前,实验者首先对其中一半被试的反应进行测量。而完成了实验处理后对剩余的另一半进行测量。然而,那些稍后得到测量的被试同样被分为两半,其中一半接受处理而另一半则不接受。此外,请读者注意,这一设计的一个显著特征。它可能证明自变量的概念地位并不受限于单独的一套特殊处理上。通过使用两套不同的处理(M1与M2),这两套不同的处理均源自于概念上相同的自变量,可以得出从具体的观察到抽象变量上的一般化结论。
从上述描述中你可以发现,无论在任何设计中,随机化都是非常重要的。当然,同样重要的是,对被试的观察不能干扰由实验处理引发的行为结果。
表A.1 使效度缺乏最小化的一些实验设计

此处的随机化既包括将被试随机分配至不同被试组,又包括随机决定对照组是否接受处理。
[1]当一组数据的变异与相应的另一组的数据的变异(例如,来自同一个体的两次测验分数)有关联时,可运用数学上的相关系数r来表述结论。相关系数值的取值范围为-1到+1。当r=0时,两组数据相互之间没有关联。r大于0表示两组数据中的变异有一个共同的方向:A增加那么B也增加。r小于0则意味着A与B有着相反方向。随着r越接近于+1.0或者-1.0,那么就越有可能通过一个已知事件来预测另一个,即根据关于一组观测中变异的知识来解释另一组观察的变异。
[2]本附录的以下部分大多源自Campbell与Stanley(1963)的著作。