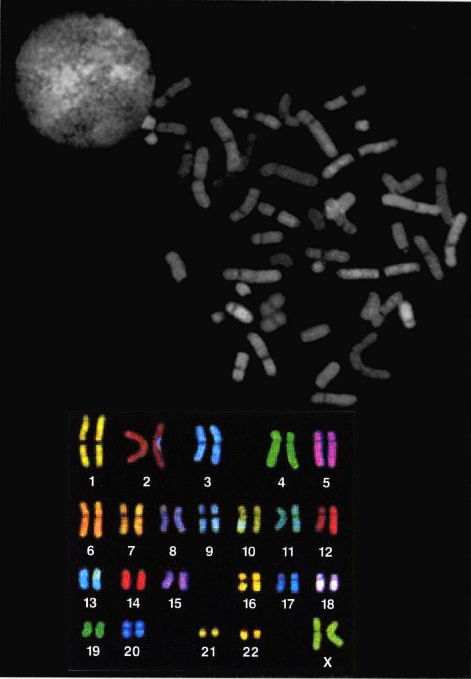
以染色体专用荧光着色剂上色的整套人类染色体。每个细胞里的染色体总数是46个——完整的两套,各从父方和母方得到一套。基因组是一套23个染色体,亦即23个很长的DNA分子。
人体复杂得令人迷惑。传统上,生物学都是专注于一小部分,试图详尽地了解它。在分子生物学来临后,这个基本做法仍然没有改变。科学家大多仍只擅长一个基因,或涉及某条生化路径的一群基因。但任何机器的零件都无法独自运作。如果我要研究轿车引擎的化油器,就算是把它研究彻底,我还是无法了解引擎的全部功能,更不用说整辆车要了解引擎的功能及运作原理,我必须研究整台引擎才行。我得把化油器放进引擎运作的整体架构内,当做一个发挥功用的零件,就跟许多其他的零件一样。基因的情况也一样。若要了解决定生命的遗传过程,我们不仅必须对个别的基因或路径有详细的知识,也需要把这些知识放进整个系统,也就是“基因组”的架构里去看。
基因组(genome)是存在于每个细胞核里的遗传指令。(事实上,每个细胞包含两个基因组,分別来自父方和母方:我们从父母继承到两个染色体复本,这让我们每个基因都有两份,因此有两个基因组。)基因组的大小视物种而不同。从人类单一细胞内DNA数量的测定值来看,我们可以估计人类基因组(单一细胞核内所含的一半DNA)大约包含31亿个碱基对,也就是3100000000个A,T,G或C。
基因攸关我们生命中每一个成功与不幸,甚至我们最终的命运。它们与所有的死亡原因多少都有些关系,只与意外事故无关。纤维囊泡症和泰赛二氏症(Tay-Sachs)等直接由基因突变引起的疾病,是最明显的例子之一。但是还有许多其他的基因,同样攸关生死,只不过运作方式比较迂回,它们会让我们容易罹患常见的杀手疾病,像是癌症和心脏病,这两种病可能会在家族里遗传。甚至我们对麻疹和普通感冒等传染性疾病的反应,也与基因有关,因为免疫系统是由我们的DNA所控制的。老化基本上也是一种基因现象:变老所呈现的一些表现,多少反映出我们的基因在一生中所累积的突变。因此,如果要彻底了解这些攸关生死的遗传因子,并最终能处理与它们有关的问题,就必须编出一份我们身体里所有遗传因子的清单。
最重要的是,人类基因组包含我们之所以为人的关键。人类和黑猩惺的受精卵在刚形成时,至少在表面看来是无法分辨的,但一个包含的是人类基因组,另一个是黑猩猩基因组。从这个受精卵开始,一个相当简单的细胞会变成极度复杂的成体,例如人就是由一百兆个细胞所构成的,这整个过程就是由DNA一手操控。但是只有黑猩猩基因组能制造出黑猩猩,也只有人类基因组能制造出人类。人类基因组包含大量的组合指令,控制每一个人的发育成长。人类的本性就是写在这本指令书里。
在了解其中的利害关系后,你可能会认为支持人类基因组DNA定序计划,就像要人支持妈妈和苹果派一样,不会有多少争议。有哪个脑筋清醒的人会反对?然而,在20世纪80年代中期,学者专家首度开始讨论基因组定序的可能性时,仍然有人认为这是不太可能实现的构想,有些人则认为这个构想的野心大得不像话,就像跟维多利亚女王时代的热气球驾驶人建议要送人上月球一样。
再也想不到的是,结果竟然是一个望远镜在偶然间促成了“人类基因组计划”(Human Genome Project, HGP)。在80年代初,加州大学的天文学家提议兴建世界最大、功能最强的望远镜,成本预计在7500万美元左右。当霍夫曼基金会(Max Hoffman Foundation)承诺赞助3600万美元时,加州大学感激地同意以这位慷慨赞助人之名来替这个计划命名。只可惜这种感谢方式反而让剩余经费的筹措事宜变得复杂起来。其他的募款对象不愿意提供经费,兴建一个已经以他人之名命名的望远镜,这个计划就此进退不得。最后,另一个更富有的慈善机构凯克基金会(W. M.Keck Foimdation)介入,表示愿意赞助这项计划的所有费用。加州大学很高兴地接受,无论有没有霍夫曼的支持都一样。(新的凯克望远镜建于夏威夷的冒纳凯阿山[Mauna Kea]山顶,于1993年5月全面启用。)霍夫曼基金会不愿屈居凯克基金会之下,于是撤回资金,这时加州大学的行政主管察觉到这是一个3600万美元的机会,特别是加州大学圣克鲁斯分校的校长辛谢默(Robert Sinsheimer),他知道霍夫曼基金会的钱足以支持一项重要的研究计划,而这将足以“让圣克鲁斯扬名于世”。
辛谢默是分子生物学家,非常渴望他的领域也能跻身经费庞大的科学“大联盟”。物理学家有昂贵的超级碰撞加速器,天文学家有7500万美元的望远镜和人造卫星,为什么生物学家不能有高档昂贵的计划?于是他建议圣克鲁斯大学成立一家研究所,专门为人类基因组定序;1985年5月,一项会议在圣克鲁斯召开,讨论辛谢默的构想。整体而言,与会者认为这个计划野心太大,但同意初期的研究重点应放在对医学具有重要意义的特定基因组领域。最后这场会议却毫无成果,因为霍夫曼的钱并未进入加州大学的财库。但是圣克鲁斯这场会议仍播下了种子。
让人类基因组计划迈出第二步的推手,也令人感到意外:美国能源部(DOE)。它的任务当然是以美国的能源需求为主,但是其中至少有一项任务与生物有关:评估核能对健康的危害。因此,能源部一直都有提拨经费,追踪长崎和广岛原子弹爆炸事件的幸存者及其后代,研究他们遗传基因受到的长期损害。还有什么比人类基因组的完整参考序列更适合用来确认辐射造成的突变?1985年秋天,能源部主管健康与环境研究的德利西(Charles DeLisi)召开了一个会议,讨论能源部的基因组计划。生物界人士充其量也是抱着怀疑态度,斯坦福遗传学家波兹坦(David Botstein)谴责这个计划是“能源部为失业的炸弹制造者所做的计划”,当时的国家卫生研究院院长温嘉丹(James Wyngaarden)则将这个构想比喻为“国家标准局提议建造B-2隐形轰炸机”(难怪国家卫生研究院后来会成为人类基因组计划最耀眼的一员)。然而,能源部在整个计划中仍扮演了重要角色,根据最后的统计,大约11%的定序工作是由它负责。
到了1986年,谈论基因组的声音愈来愈大。6月,我在冷泉港实验室一个重要的人类遗传学会议期间,安排了一场特别会议来讨论这个计划。前一年曾在加州参与辛谢默那场会议的吉尔伯特一鸣惊人,提出一个可怕的成本预估数字:30亿碱基对,30亿美元!这的确是一个要花大钱的科学计划。如果没有公共资助,这笔钱多得难以想像,会议中自然有人会担心,这个成败未卜的庞大计划会抢走其他一些重要研究的经费。他们担心人类基因组计划会成为科学研究最大的钱坑。就科学家个人对事业的企图心而言,做这个计划再怎么样也不划算。人类基因组计划在技术上当然有许多挑战,但它在智识层面并不能让人感到非常振奋或能带来多少名声。这整个工作实在非常庞大,即使是很重要的突破也会被淹没;再说,有谁愿意把自己的一生花在永无止尽、冗长无聊的定序工作上?波兹坦就提醒大家要非常谨慎:“这会改变科学的结构,使我们所有人,尤其是年轻人,都被这个庞大的工作绑住,就像航天飞机一样。”
尽管反应并不怎么热烈,但那次冷泉港的会议却让我坚信,为人类基因组定序势必很快会成为国际科学界的优先要务,而当这成真时,国家卫生研究院应该担任一个主要的角色。我说服了麦克道尔基金会James S. McDonnell Foundation),请他们赞助一项由国家科学院(NAS)所主持的对相关议题的深入研究。由于有加州大学旧金山分校的艾尔伯特(Bruce Alberts)担任委员会的主席,我确信所有的构想都会受到最严格的监督。前不久艾尔伯特才发表一篇文章,警告“大科学”的兴起,势将排挤世界各地的个别实验室在传统研究上的无数创新贡献。在不确定我们的小组会达成什么意见之前,我已经和吉尔伯特、布雷纳和波兹坦加入了15人的委员会;翌年(1987)我们便努力规划出未来的基因组计划细节。

催生人类基因组计划:1986年,大力支持这项计划的哈佛大学教授吉尔伯特(左)和斯坦福大学的波兹坦在冷泉港实验室争论的情景。
在那段早期岁月,吉尔伯特是支持人类基因组计划最有力的人士。他贴切地指出,这“在调查人类功能的各个层面上,是一个无与伦比的工具”。在协助成立Biogen生技公司、尝过科学与商业结合的刺激滋味后,他在基因组上看到了崭新的大好商机。因此在短暂任期后,他就把在这个委员会的职位转让给华盛顿大学的奥森(Maynard Olson),以回避任何可能的利益冲突。分子生物学已经证明具有创造庞大商机的潜力,而吉尔伯特认为没有必要再筹措公共资金。他推论,只要拥有大型定序实验室,私人公司就可以做这个工作,然后把基因组的信息卖给制药厂和其他利益团体。1987年春天,吉尔伯特宣布筹组“基因组公司”(Genome Corporation)的计划。当时对于私人拥有基因组数据的可能性,有许多强烈不满的声音(大家担忧这会让新知识不能广为利用、造福大众),但吉尔伯特对这些充耳不闻,开始筹措风险投资资金。只可惜,他因为过去担任执行长的纪录不佳而出师不捷。自从他在1982年辞掉哈佛的教职,担任Biogen的总裁后,这家公司立即在1983年亏损1160万美元,后来又在1984年亏损1300万美元。他会在1984年12月回到哈佛,躲到覆满常春藤的校墙后,也是可以理解的,不过Biogen在他离开后仍不断赔钱。吉尔伯特的新计划算不上是令人垂涎三尺的投资案,但最终这个野心勃勃的计划之所以失败,与其说是经营管理能力的缺失,不如说是非他所能控制的大环境所致:1987年10月美国股市大崩盘,基因组公司的成立计划也随之崩解。
其实,吉尔伯特惟一犯的错就是超前他的时代。在他的成立计划胎死腹中整整10年后才成立的赛雷拉基因公司(Celera Genomics),在规划上跟吉尔伯特的构想大同小异,但赛雷拉基因公司却相当成功。吉尔伯特的风险投资事业引发外界对DNA序列数据可能为私人拥有的疑虑,而随着人类基因组计划的进展,这些疑虑也逐渐成为瞩目焦点。
吉尔伯特离开后,我们的国家科学院委员会在艾尔伯特的领导下,规划出一个在当时来讲很合理的计划,事实上,人类基因组计划多少是根据这些规划来执行的。我们预测的成本及时程后来也证明相当准。拥有个人计算机的人都知道,科技会随着时间变得更好、更便宜,因此我们建议把大部分实际的定序工作延后,直到技术的成本效益达到合理程度时再开始,并把改善定序技术列为优先事项。为了达到这个目标,我们建议先找出较简单生物的基因组序列(它们的基因组比较小)。从中获得的知识本身就很有价值(可以在最终找出人类基因组序列后拿来作比较,得到许多启发),同时也可以借此精进我们的定序技术,供其后解开庞大基因组之用。非人类研究目标的不二之选自然是遗传学家的旧爱:大肠杆菌、酵母菌、线虫(学名C. elegans,它在布雷纳带动下成为研究宠儿),以及果蝇。
同时,我们应把重点放在尽可能建立精确的基因组图谱上,而且基因图谱与实质图谱都要建立。基因图谱(genetic mapping)决定相对位置,也就是染色体上基因地标(genetic landmark)的顺序,如同“摩根的孩子们”最初对果蝇染色体所作的研究。实质图谱(physical mapping)则是实际确认这些基因地标在染色体上的绝对位置。(基因图谱告诉我们,二号基因位于一号和三号基因之间;实质图谱告诉我们二号基因距离一号基因一百万个碱基对,而三号基因是在染色体上再往后两百万个碱基对的地方。)基因图谱呈现出基因组的基本结构;实质图谱则可以提供定序仪(sequencer)染色体上的定位锚,然后我们便可以借由参照这些定位锚,决定各个序列片段在染色体上的位置。
我们估计整个计划大约费时15年,成本每年约2亿美元。我们做了更多复杂的计算,但都脱离不了吉尔伯特每个碱基对1美元的估算。每发射一次航天飞机耗资4.7亿美元,基因组计划的费用相当于发射六次航天飞机。
我们的报告在1988年2月出炉。基因组的草图是在2001年发表。在我撰写本书的期间,全球各地的定序实验室不断交出更多成果,到了2003年,也就是发现双螺旋体50周年,我们这个委员会的报告出炉15年时,我们已看到定序工作全部完成。
国家科学院委员会仍在商议时,我到参众两院审查国家卫生研究院预算的卫生小组委员会,跟他们的重要成员会谈。国家卫生研究院的院长温嘉丹支持基因组计划,而且根据他的说法是“从一开始”就支持,但是国卫院里眼光较为短浅的人士却表示反对。我在建议以3000万美元让国卫院参与基因组研究时,特别强调基因组序列的知识对医学的影响。国会议员跟我们其他人一样,也会有挚爱的人因为癌症等与基因有关的病症去世,应该也可以体会,解开人类基因组序列能够协助我们对抗这类疾病。最后,我们获得1800万美元。
在此同时,美国能源部也以强调这个计划将是一项科技伟业而争取到1200万美元的经费。我们必须记得:在那个年代,制造技术是日本居于领导地位;底特律遭逢被日本汽车业赶过的危机,许多人担心美国在高科技领域的优势将会是下一个倒下的骨牌。据说当时三大日本集团(松井、富士和精工)已经联合起来,准备生产一天能替100万个碱基对定序的机器。最后证明这只是误传,但这类疑虑的确让美国基因组计划获得动力,如同当年要赶在苏联之前把美国人送上月球的情形。
1988年5月,温嘉丹要求我主持国卫院的基因组计划。在我表明不愿为此放弃冷泉港实验室的主任职位后,他设法替我安排以兼职方式来做国卫院的工作。我无法再拒绝。18个月后,人类基因组计划成为一股无法阻挡的力量,而国务院的基因组办公室也升级为人类基因组研究国家中心(National Center for Human Genome Research),我被任命为首届主任。
我的工作是要向国会争取更多经费,同时确保这些经费都运用得当。我最关心的事情之一,是人类基因组计划的预算能跟国家卫生研究院其他计划的预算分开。人类基因组计划不能危及其他科学的生存;如果我们的成功会让其他科学家理直气壮地说,他们的研究成为这个庞大计划的牺牲品,我们就没有成功的权利。同时,我也认为,身为推动这项创举的科学家,我们应该显示出,我们了解它的深远影响。人类基因组计划不仅是定出A,T,G,C的位置,在各个层面上,它都是人类所能获得最珍贵的知识之一,甚至可能回答与人性有关的最基本的哲学问题。我决定我们应该把总预算的3%(这比例虽然不高,金额却很庞大)用于研究这个计划对道德、法律与社会的影响。后来在参议员戈尔(Al Gore,其后曾出任副总统)的敦促下,这个比例提高至5%。
基因组计划的国际合作模式也是在早期阶段就已奠定:由美国主导这项计划并执行超过半数的工作;其余的部分主要由英、法、德、日负责。尽管英国的研究委员会(Medical Research Council)多年来致力遗传与分子生物学的研究,但在这项计划上贡献并不多。它和英国的整体科学一样,都受到撒切尔夫人缺乏远见的经费紧缩政策影响。幸好民间的生物医学组织维康信托基金会(Wellcome Trust)伸出援手;1992年,维康在剑桥外特别成立一所定序机构,并命名为桑格中心。在国际合作方面,我决定把基因组依照不同的部分分配给各个国家。以这样的方式,参与国应该会感到自己有具体的努力目标,例如特定染色体的一臂,而不是跟一群无名的克隆株苦苦奋斗,比如日本的重点主要是第21号染色体。遗憾的是,为了尽快完成整个工作,最后仍无法按这个条理来做,结果证明:要把基因组图谱按世界地图分配,毕竟太过困难。
从一开始,我就认为人类基因组计划无法通过无数的“小工作”来完成,亦即无法在过多实验室的参与下完成。整个后勤作业会太过混乱,也无法获得规模化与自动化的好处。因此,华盛顿大学、斯坦福大学和加州大学旧金山分校、密歇根大学安娜堡分校、剑桥的麻省理工学院,以及休斯敦的贝勒医学院(Baylor College of Medicine)很早就成基因图谱中心。能源部的工作最初集中在济斯阿拉莫斯(Los Alamos)和利弗莫尔(Livermore)国家实验室,最终都移到了加州的沃尔纳特克里克市(Walnut Creek)。
接下来要做的事是研究和发展替代性的定序技术,希望能把整体成本减至每个碱基对50美分左右。我们展开了数个试行计划,讽刺的是,最后很成功的荧光染剂自动定序法(fluorescent dye-based automated sequencing)在这个阶段的进展并不特别好。事后回顾,自动化机器定序的试验工作,应该交由国家卫生研究院的研究员温特(Craig Venter)来做,当时他已经证明是个中好手。他曾提出申请,但最后获选的人是这项技术的原始发明人胡德(Lee Hood)。未聘用温特一事,到后来造成了很大的影响。
结果人类基因组计划并未促成大量分析DNA的新方法问世,相反地,最后是通过改良旧方法和自动化,DNA的分析量才得以逐步增加,先是数百到数千,然后增加到数百万碱基对序列。然而,有一项革命性的技术对这个计划特别重要,亦即可以大量制造特定DNA片段的技术(若要定序一段特定的DNA,就需要大量该段DNA)。在80年代中期以前,放大一个特殊的DNA区域必须使用柯恩-波耶分子克隆法:先取出想要的DNA片段,将它插入质体,再把改造后的质体插入细菌细胞。然后这个细胞会开始复制,每次都复制出先前插入的DNA片段。等细菌生长到足够的数目时,再从整个细菌群落所有的DNA中取出你要的DNA片段。虽然自从波耶和柯恩最初的实验后,这个程序已经精进不少,但仍相当繁琐又耗时间。因此,聚合酶连锁反应(PCR)的发展成功就成了一大跃进:它可以达到相同的目标,但是只需几个小时,就可以选择性地扩增你想要的DNA,而且不需要处理麻烦的细菌。

聚合酶连锁反应(PCR)发明人穆利斯和他的冲浪板。
聚合酶连锁反应是在西特斯公司服务的穆利斯(Kary Mullis)发明的。根据他的说法,“1983年4月一个星期五晚上,我手握车子方向盘,沿着蜿蜒山路开往加州北部的红杉区,就在那时,我突然有了这个构想。”在那种危险的情况中,他居然还能产生灵感,实在很神奇。倒不是因为加州北部的路特别危险,而是就像他的一位朋友告诉《纽约时报》的:“穆利斯曾在一个幻像中看到自己因头部撞到红杉而死,所以只要在没有红杉的地方,他总是一无所惧。这位朋友曾经在滑雪胜地阿斯彭(Aspen)看到穆利斯脚踩滑雪板,穿梭在快速的双向车阵,神勇地从结冰的道路中央疾滑而下。穆利斯因他的发明在1993年荣获诺贝尔化学奖,从此以后他变得更加古怪。他支持修正派的理论,认为艾滋病不是HIV所引起的,这使他的可信度和推动公共卫生的努力都打了折扣。
聚合酶连锁反应是极为简单的过程。第一步是以化学方法合成两个引子(primer),所谓“引子”是短链的单股DNA,长度通常在20个碱基对左右。这两个引子和目标DNA片段的两端具有互补的序列,它们就像是把我们想要的基因用括号括出来。我们首先从组织样本中萃取出作为模板的DNA,然后加入引子。这个模板实际包含整个基因组,而我们的目标是大量扩增想要的目标区。在加热到摄氏95度时,DNA的双股会分开。这让每个引子得以和20个碱基对的模板片段产生互补结合,在两条单股的模板DNA的一端,便会形成具有20个碱基对的双股DNA“小岛”。DNA聚合酶(这种酶能把新的碱基对合并至单股DNA上的互补位置,借此复制出DNA)只有在DNA已经是双股的位点上才会开始作用。因此,DNA聚合酶会从引子和模板片段互补结合后所形成的双股小岛启动,由每个引子开始制造与模板DNA互补的股,从而复制出目标片段。等这个过程结束时,目标DNA的总数会增加一倍。接着我们可以重复加热步骤,整个过程再来一遍:由两个引子标示出的DNA片段的复本再度倍增。这个过程每循环一次,目标片段的数目就会倍增。经过25次循环后,亦即在不到两小时内,目标DNA的数量便扩增225倍(约3400万倍)。事实上,最初由模板DNA,引子,DNA聚合酶和自由的A,T,G,C所构成的混合溶液,最后会变成目标DNA片段的浓缩溶液。
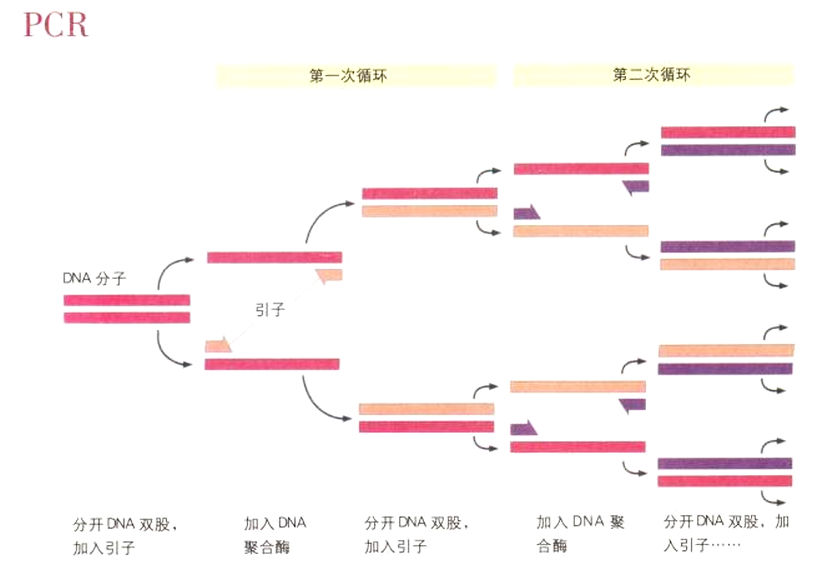
扩增目标DNA片段:聚合酶连锁反应。
在早期,聚合酶连锁反应的主要问题在于DNA聚合酶在摄氏95度时会被摧毁。因此实验人员在这25次循环中,每次都必须重新加入这种酶。聚合酶的价格昂贵,因此尽管它很有潜力,但是如果消耗量太大的话,显然就不是符合经济效益的实用工具。幸好大自然提供了解决之道。大肠杆菌是这种酶的初始来源,而最适合大肠杆菌的温度是摄氏37度,然而,有许多生物是生存在比这个温度还高许多的环境中的;这些生物的蛋白质(包括DNA聚合酶这类酶)在经过无数世代的自然选择后,已经可以适应高温。现在一般是用从黄石公园热泉里的水生嗜热菌(thermus aquaticus)分离出的Taq DNA聚合酶来引发连锁反应。
PCR立即成为人类基因组计划的主要“累活”。现在的过程跟穆利斯当初所发展的大致相同,只不过已经自动化。今日最先进的实验室都有由机器人控制的生产线,不再需要睡眼惺忪的研究生军团来执行把微量液体加入塑料管的辛苦工作。在基因组定序这种规模的计划中,这些“PCR机器人”必须使用大量聚合酶。因此,人类基因组计划的科学家对必须支付大笔不合理的权利金给PCR专利所有人罗氏制药厂,导致聚合酶的成本增加,感到特别厌恶。
字里行间:自动化定序机输出的序列。每个颜色都代表四种碱基中的一种。
DNA定序法本身也是另一个“累活”。同样地,这个方法的化学原理并非新发明:人类基因组计划使用的方法,和桑格在70年代中期发明的相同,其创新之处在于通过定序机械化,来达到大规模操作的目的。
自动化定序最初是胡德在加州理工学院的实验室发展出来的。胡德以前是高中橄榄球校队的四分卫,曾率领队友连续几年获得蒙大拿州冠军;他把从中学到的团队精神用于学术工作上。他的实验室兼容并蓄,有化学家、生物学家和工程师,这个团队果然成为技术创新的领导者。
其实,DNA自动化定序是史密斯(Lloyd Smith)和杭卡皮勒(Mike Hunkapiller)的构想。当时在胡德实验室工作的杭卡皮勒去找史密斯谈一种定序法,想对每种碱基使用不同的有色染剂。原则上,这个构想可以使桑格定序法的效率提高四倍:先前的方法要分别做四次定序反应,每次各使用一条凝胶;但采用颜色代码后,只须做一次定序反应,总共只需要一条凝胶。起初史密斯的反应很悲观,担心这个方法使用的染剂量太少,无法侦测。但他不愧是激光应用专家,很快就想到解决办法,亦即采用在激光下会发出荧光的特殊染剂。
按照标准的桑格定序法,不同大小的DNA片段会在凝胶中按大小排列,每个片段都用与其末端的双脱氧核苷酸相对应的荧光染剂加上标志,该片段发出的颜色就可以显示它具有哪个碱基。然后再以激光扫过胶体底部,让每个片段发出荧光,这时电眼会侦查每个DNA片段发出的颜色,接着这个信息会直接输入计算机,省去了麻烦的人工输入数据过程。杭卡皮勒在1983年离开胡德的实验室,加入新成立的仪器制造商——应用生物系统公司(Applied Biosystems Inc.,ABI)。后来率先制造出商用史密斯-杭卡皮勒定序仪的,就是这家公司。从此以后,定序过程的效率大幅改善:笨拙缓慢的胶体被高效能的毛细管系统取代,细长的毛细管可以非常快速地将DNA片段按大小分类。这家公司目前最新一代的定序仪速度更是超快,比原型快上千倍。它们所需的人工极少(每24小时大约只需15分钟的人工),一天就可以定序50万个碱基对。最终就是因为有这项技术,基因组计划才得以实行。
在人类基因组计划的第一阶段,随着DNA定序策略不断改进,建立图谱的脚步也加快了。近期目标是找出整个基因组的粗略轮廓,让我们得以决定序列中每个区段的位置。基因组必须划分为易于处理的一个个区块,我们要建立的,正是这些区块的图谱。起初我们用人造酵母菌染色体(yeast artificial chromosome, YAC)来达成目标,这是奥森发明的方法:把大块的人类DNA片段植入酵母菌细胞内,在植入后,这些YAC会跟正常的酵母菌染色体一起复制。但是在将一百万碱基对的人类DNA片段植入单一的YAC时,发现出了问题:这些片段会更换位置。既然建立图谱就是要找出染色体上的正常基因顺序,序列更换可以说是最糟糕的情况。这时纽约州布法罗(Baffalo)的德·荣(Pieter de Jong)发展出来的人造细菌染色体(bacterial artificial chromosome, BAC)成了救星。BAC比较小,只有10万到20万个碱基对长度,换位的情况也少得多。
对那些直接负责建立人类基因组图谱的人(波上顿、艾奥瓦州、犹他州和法国的研究小组)来说,最重要的头几步是找出基因标志(genetic marker):两个人染色体上的同一段DNA会有一个或一个以上的碱基对不同,这些不同的位点即称做基因标志(亦称遗传标志),它们可以作为地标,引导我们破解整个基因组。在柯恩(Daniel Cohen)和魏森巴赫(Jean Weissenbach)的领导下,法国的Cénéthon研究所很快就建立起极好的图谱;Cénéthon是由法国肌肉萎缩症协会赞助的、类似工厂的基因组研究机构。如同英吉利海峡对岸的维康信托基金会,这家法国慈善机构弥补了政府赞助不足所留下的部分经费缺口。在最后的冲刺阶段,必须利用BAC来建立详细的实质图谱时,麦克弗森(John McPherson)在华盛顿大学基因组中心所领导的计划贡献最大。
正当人类基因组计划热烈展开之际,有关执行它的最佳方法也争论不断。有些人指出,人类基因组中有一大部分是我们这一行谑称的“垃圾”,也就是显然不负责任何编码工作的DNA片段。事实上那些为蛋白质编码的片段(亦即基因)仅占整个基因组的一小部分。有些批评者诘问道:既然如此,我们为什么要定序整个基因组,为什么要耗费心力去管那些“垃圾”?其实有一种极度快速但马虎的方式可以替基因组里所有编码基因拍张“快照”,方法是利用本书第五章描述过的反转录酶。从任意一种类型的组织中纯化出信使RNA样本;如果你的来源是脑,就会得到脑部所有表现型基因的RNA样本。然后你可以利用反转录酶制造这些基因的DNA复本(称为互补DNA,cDNA),然后定序这些cDNA。
然而这个快速马虎的做法无法取代破解整个基因组。我们现在已经知道,基因组最有趣的部分有许多是位于基因以外,它们构成控制基因启闭的机制。以刚才脑组织的cDNA分析为例,你只能对在脑部是开启的基因有概略的了解,但是对它们的启动过程毫无概念:将DNA股复制至信使RNA的RNA聚合酶,并不会把DNA中极重要的调节区段转录到RNA上。
在经费短缺的英国医疗研究委的会任职的布雷纳,率光采取以eDNA为主的方法,大规模地发现基因。他认为定序cDNA,是在只有少数经费时,最符合成本效益的方法。由于渴望从这些序列获取商业利益,英国的医学研究委员会不准布雷纳发表成果,直到英国制药商准备好从中获利后,才让他发表。
温特到布雷纳的实验室参观时,对于他们的cDNA策略大感惊异,简直等不及要赶回他在华府市郊国家卫生研究院的实验室,用这种技术制造出一个新基因宝库。即使只定序出每个基因的一小部分,温特就可以判定它是否是科学上的新发现。在1991年6月,国家卫生研究院的官员敦促他为337种新基因申请专利,尽管他对其中许多基因的功能一无所知。一年后,在更广泛地运用这个技术后,温特又向专利局申请了2421个序列的专利。我认为,不知道这些序列的作用,却盲目申请它们的专利,是令人无法容忍的。既然莫名其“妙”,这么做到底在保护什么?这只不过是先发制人,垄断其他人日后作出真正重大发现所可能带来的商机。我向国家卫生研究院高层人士力陈其非,但徒劳无功。他们仍坚持为这种做法解释开脱(后来这政策也逆转了),而这也意味着我在政府官僚体系里的职业生涯即将结束。当国家卫生研究院的院长希利(Bernadine Healy)迫使我在1992年辞职时,我心中可以说五味杂陈。在华盛顿这个压力锅熬了四年,已经够了。但对我来说真正重要的是,在我离开时,人类基因组计划已经步上正轨。
温特发现替基因组的片段申请专利,可能带来许多商业机会后,在这方面的胃口大开。但他想鱼与熊掌兼得:继续留在可自由分享信息但薪水很少的学术圈,同时进入商业圈,在取得专利权并赚上一票之前,他的发现将是秘密。在像是他的教父的风险投资家斯坦伯格(Wallace Steinberg)协助下,温特的梦想终于在1992年成真。斯坦伯格是丽奇(Reach)牙刷的发明人,他提供7000万美元成立了两家机构。一家是非营利事业,基因组研究所(The Institute for Genome Research, TIGR,英文发音与tiger[老虎]相同),由温特主持另一家姐妹公司是人类基因组科学公司(Human Genome Sciences, HGS),由商业倾向的分子生物学家黑索廷(William Haseltine)领导。它们的运作方式是:基因组研究所研究引擎,负责挖掘出cDNA序列;人类基因组科学公司走商业路线,负责营销这些发现。在前者发表数据前,后者会有六个月时间评估这些数据,但在研究显示它们有发展新药的潜力时,评估时间则延长为一年。
温特从小在加州长大,最初宁可去冲浪,也不想继续求学。但是在越战时担任医护兵的一年间受到一些心理创伤后,似乎让他立定志向。回美国后,他在短时间内从加州大学圣地亚哥分校拿到生理学和药理学的学士与博士学位。他之所以会从学术界转往商业界发展,从他个人的财务看来也相当合理:
根据他自己的解释,他在创建美国基因组研究所时,银行里只有2000美元存款。但他很快就扭转财运。1993年初,急于赶上基因组热潮的英国制药公司史克必成(Smithkline Beecham)支付给温特1.25亿美元,取得对他那张愈写愈长的新基因名单的独家商业使用权。一年后,《纽约时报》揭露,温特在人类基因组科学公司拥有10%的股份,价值1340万美元。他不愁没钱花了,重金砸下400万美元买了一条82英尺长的赛艇,还在大三角帆上印上他20英尺的巨幅画像。
1995年,人类基因组科学公司对称为CCR5的基因申请专利。他们的初期序列分析显示,这个基因为免疫系统中一种细胞表面的蛋白质编码,因此值得“拥有”,因为这类蛋白质有可能成为免疫系统药物起作用的目标。黑索廷的公司为类似的基因提出140项专利申请,CCR5是其中之一。1996年,研究人员发现了CCR5在HIV病毒入侵免疫T细胞的途径中所扮演的角色。他们也发现CCR5的突变是使人对艾滋病产生抵抗力的原因:当时已经观察到,有些男同性恋重复接触HIV,却一直没有染病,最后发现这些人都拥有突变的CCR5基因。因此,无论是当时或现在,CCR5都注定要在我们对抗HIV的努力上扮演重要的角色。找出CCR5在艾滋病传染中扮演的重要角色,需要辛苦的研究和扎实的科学工作,但在这两方面都毫无贡献的人类基因组科学公司却有机会坐收庞大的利益,只因它最早宣称拥有那个基因;而且CCR5专利将迫使每次应用这个知识的人都得缴一笔费用,这等于对每一分钱都很重要的医学研究工作征重税。但黑索廷的反应一点也不惭愧:“如果在专利获得核准后,有人将这个基因用于药物开发……并且是基于商业用途,他们就是侵害了专利权。”他还相当愤慨:“我们不但有权要求损害赔偿,而且是两三倍的赔偿。”

基因组计划朝商业发展:1995年5月美国《商业周刊》以黑索廷(左)及温特为封面人物,称他们为“基因之王”。
在20世纪70年代,黑索廷是哈佛的研究生,由我和吉尔伯特共同指导。后来他在医学院的达纳—法伯癌症研究中心(Dana Farber Cancer Center)管理一个创新的HIV研究中心。但一直到和身价不菲的社交界名媛海曼(Gale Hayman,80年代人人抢着拥有的香水品牌Giorgio Beverly Hills的创造者)结婚后,他才获得高知名度,所以他在成立人类基因组科学公司时,银行存款绝对不只2000美元。他在成为企业家之前,就曾因搭乘喷气式飞机四处旅行,引来哈佛医学院实验室同事的非议和讥讽。“黑索廷和上帝的差别在哪里?”答案:“上帝无所不在,黑索廷也无所不在,就只不在他应该在的波士顿。”
温特和黑索廷抢着替他们用cDNA定序法找到的每一个人类基因申请专利,这当中极少牵涉到技术或创新发明。他们这两家生技公司,就像霸占游戏场里所有玩具,不让别人玩的孩子一样。
这类投机性的基因专利对医学的研发造成严重影响,长期而言,也会导致医疗选择变得更少和更差。事实上,这些投机者等于取得了对潜在药物目标亦即尚未问世的药物或疗法所针对的蛋白质的专利。对大多数的大制药厂来说,生技公司在对基因功能仅有微薄或根本没有生物信息的情况下,针对药物目标所提出的基因专利,已经成为毒药。这些基因的垄断者要求庞大的权利金,造成财务失衡,对药物的发展不利;其实在研发合格药物的过程中,克隆药物目标顶多占1%的工作而已。此外,如果一家公司制造出针对特定目标的药物,同时又拥有与该目标相关的基因专利,那么这家公司没有理由要立即针对这个目标发展更好的药物。原因就在于如果你拥有专利,而别家公司就算可以合法进行研发,也会因成本高得吓人而不愿参与竞争,那么你又何必投资于研发?
美国基因组研究所、人类基因组科学公司和史克必成制药公司三雄鼎立,在未来有可能垄断人类基因序列的商业运用,这情形让分子生物产学两界都产生警觉。1994年,史克必成在制药业中的老对头默克公司(Merck)了提供1000万美元让华盛顿大学的基因组中心定序人类cDNA,并公开发表研究结果,给了人类基因组科学公司一巴掌。
大约在温特和黑索廷的公司开始把基因组商业化时,柯林斯(Francis Collins)继我之后出任国家卫生研究院的基因组研究中心主任。柯林斯是最佳人选,他是建立基因图谱的一把好手,在数个重大疾病的基因方面经验丰富,包括与纤维囊泡症、纤维神经瘤病(neurofibromatosis,即所谓的“象人”病)和亨廷顿氏症有关的基因。如果有人颁发人类基因组锦标赛初赛(以建立重要基因的图谱及找出其特征为目标)的奖项,柯林斯无疑会是大赢家。但是他自有记分方式:他最爱的交通工具是本田的夜鹰机车,每次他的实验室又建立一个新基因的图谱时,他的同事都会在他的安全帽上加一个印花图案。
柯林斯在弗吉尼亚州谢南多厄河谷(Shenandoah Valley)一个95英亩大、没有自来水的农场长大。起初他在家里自学,由分别是戏剧教授和剧作家的双亲教导,他7岁时就已写出《绿野仙踪》(The Wizard of Oz)的舞台剧本并自任导演。但是科学的魔力把柯林斯拖离戏剧生涯;在耶鲁完成物理化学博士学位后,他进入医学院,从此开始医学遗传学领域的研究生涯。柯林斯属于科学界的罕见品种:他是一位对宗教非常虔诚的科学家。他曾回忆说,在大学时,“我是非常惹人厌的无神论者。”但这一切在医学院时改变,那时“我看到人们在病情严重时为生存而战,有许多人战败。我看到有些人依赖信仰,也看到信仰带给他们的力量。”柯林斯不仅为人类基因组计划带来卓越的科学见解,同时也注入他的前任所缺乏的一个精神层面。到了90年代中期,人类基因组图谱的初稿已经完成,而定序技术也快速发展后,该直捣核心去研究A,T,C和G了——定序时机终于来临。我们仍遵循早先由国家科学院委员会制定的方针,先从一连串的模型生物做起:先是细菌,然后是比较复杂(亦即基因组比较复杂)的生物。低等的线虫是第一个非细菌的大挑战,英国桑格中心的萨尔斯顿(John Sulston)和美国华盛顿大学的瓦特斯顿(Bob Waterston)联手研究线虫,成果斐然,为国际合作立下良好楷模。线虫的序列在1998年12月发表,一共有9700万个碱基对。线虫顶多只有书页上的逗号那么大,细胞数目是固定的959个,却拥有大约2万个基因。

萨尔斯顿在美国的合作伙伴瓦特斯顿出身普林斯顿大学,主修工程学。他为自己管理的华盛顿大学大型定序中心引入了许多工程学智慧。瓦特斯顿具备从己知事物推测未知事物的能力,也就是可以从小事开始,完成大事。他在陪女儿慢跑时发现自己很喜欢跑步,现在他己是马拉松好手。他的定序小组在第一年时,只找出了线虫序列的4万个碱基对,但是在数年之内,他们的成果便巨量增加,瓦特斯顿也是最早呼吁全面展开人类基因组定序工作的人士之一。

国际合作:英国和美国的科学家率先完成第一个复杂生物(线虫)的基因组定序工作;这个计划的主持人瓦特斯顿(图左)和萨尔斯顿仍会找时间轻松一下。
乍看之下,萨尔斯顿似乎不适合在“大科学”中担任领导人。他大半职业生涯都花在用显微镜来观察线虫上,以便能一个细胞一个细胞地精确描述线虫每一个发育过程。他是英国国教牧师之子,留了一脸胡子,像个老伯伯。他一生支持社会主义,笃信商业与人类基因组毫无关系。如同柯林斯,他也是机车迷,以前经常骑着他那辆的机车往返于他位于剑桥外的家和桑格中心之间,一直到他在车祸中受了重伤,而他的机车也变成他口中“比螺钉和螺帽多不了多少”的废铁后,他才停止这么做。当时正值人类基因组计划逐渐加快脚步之际,车祸发生后,赞助桑格中心的维康信托基金会才惊恐地得知,原来这个计划的科学领导人每次上班都在冒生命危险。基金会董事长奥吉维(Bridget Ogilvie)说:“亏我们在这家伙身上投资了这么多钱!”
然而,正当人类基因组计划的国际团队开始定序模型生物,准备全力朝最终目标前进时,分子生物界的一场大地震却撼动了整个计划。
温特和美国基因组研究所一直进行得很顺利。在运用cDNA基因发现策略数年后,温特开始对整个基因组的定序产生兴趣。在这一点上,他仍很相信自己那套方法的优越性。人类基因组计划是先仔细地建立DNA不同片段的位置,然后才开始实际的定序工作。这样的话,我们事先已经知道A片段位于B片段旁,等到要把它们连成最后的序列时,便可以找出它们之间的重叠部分。但温特偏好“全基因组随机”(whole genome shotgun, WGS;亦称“全基因组散弹枪”)定序法,这种方法不做初期的图谱建立工作,而是直接把基因组随机分成一个个片段,找出它们的序列,然后把这些序列全部输入计算机,靠计算机按照重叠部分把它们排成正确的顺序,并不借助预先定好位的信息。温特和他的团队证明这种蛮干的做法实际可行,至少可用于破解简单的基因组:1995年,他们发表了用这方法找出的流感嗜血杆菌(Haemophilus influenzae)基因组序列。
但是全基因组随机定序法是否适用于大型复杂的基因组,例如人类基因组,则尚未获得证实。问题在于重复,亦即相同序列的片段会在基因组的不同位置发生,基本上,这些重复有可能使全基因组随机定序法无法成功,也很有可能误导最精密的计算机演算。举例来说,如果有一个重复片段发生在A片段和P片段内,计算机有可能误把A排在Q旁,而不是它原本应在的位置,即B的旁边。人类基因组计划的研究小组在考虑采取全基因组随机定序法时,也讨论过这个可能性,而根据西雅图的葛林(Phil Green)的精密计算,这个小组的结论是:由于人类基因组有垃圾DNA这些大量冗长的重复序列,所以这个方法可能会造成混淆。
1998年1月,制造自动化定序仪的应用生物系统公司总裁杭卡皮勒邀请温特去参观他的最新机型PRISM3700。虽然温特对这台机器大为赞赏,但他对接下来的事毫无心理准备。杭卡皮勒建议温特成立一家新公司来进行人类基因组定序,由应用生物系统的母公司Perkin Elmer提供资金。温特毫不犹疑地舍弃了美国基因组研究所,反正他跟人类基因组科学公司的黑索廷关系也早已恶化。他立刻成立了新公司,也就是后来的赛雷拉基因公司,它的座右铭是:“速度最重要,发现不能等。”他们计划以全基因组随机定序法定序整个人类基因组,并且釆用三百台杭卡皮勒的机器加上许多计算机,其计算能力仅次于美国国防部。这个计划将费时两年,耗资在2亿美元到5亿美元之间。
这个消息传开时,刚好是后来所谓的“公共”人类基因组计划(有别于民间的“私人”计划)领导人即将在冷泉港实验室会面的前夕。含蓄地说,大家对这消息都不太能接受。我们这个全球性的计划已经花掉大约19亿美元的公共资金。如同《纽约时报》的说法,现在我们除了老鼠基因组的序列以外,可能拿不出别的成绩,而温特则可以轻松地抢走这场竞赛的圣杯:人类基因组。最令人不悦的是温特对后来被称为“百慕大原则”(Bermuda Principles)的做法嗤之以鼻。1996年,人类基因组计划在百慕大开会(温特也参加了),决议只要一获得序列数据,就立即公布。我们一致同意基因组序列应该是公共财产。现在成为叛徒的温特却有不同的想法:他宣称会延后三个月才公布新的序列数据,以便把专利权卖给有兴趣购买优先获知权的制药公司和其他任何人士。
幸运的是,维康信托基金会的摩根(Michael Morgan)适时提供了一剂强心针。在温特公布消息后短短数天内,摩根宣布维康将把提供给桑格中心的资金增倍,使总金额达到3.5亿美元左右。虽然这次宣布的时机看起来好像是在直接响应温特的挑战,事实上增加经费一事已酝酿了一段时间。不久,美国国会也提高了对公共人类基因组计划的补助。竞赛就此展开。其实,从一开始就注定至少会有两个优胜者。惟有两组人类基因组序列存在,科学才会受益,因为有两组结果,才能互相比对检视(在超过30亿碱基对的情况下,势必会有一两个错误)。另一个赢家无疑是应用生物系统公司:他们能卖出更多PRISM定序仪了,毕竟公共人类基因组计划中大多数的实验室现在都必须购买它们,才赶得上温特的进度。
在接下来的几年间,私人与公共计划领导人之间尖酸的言论交锋,成为报纸科学版中固定出现的题材。这些一来一往的言辞,终于连克林顿总统也看不下去,他对科学顾问说:“把这件事搞定……让这些家伙合作。”尽管如此,定序工作仍继续进行,而温特也证明全基因组随机定序法可用于相当庞大的基因组,通过和公共计划中负责研究果蝇的机构合作,他在2000年初宣布完成果蝇基因组的草图。然而,果蝇基因组仅含有极少的重复性垃圾DNA,因此赛雷拉基因公司成功组合了它,并不能保证全基因组随机定序法也适用于人类基因组。

DNA定序进入量产:麻省理工学院的怀特海德研究所。
在迎接赛雷拉的挑战上,最重要的人物莫过于兰德(Eric Lander)。因为设想出几近完全自动化的定序过程、由机器人取代技术人员的人就是他,而拥有冲劲、能使这个设想成真的人也是他。从他的履历就可看出,他的确是很有冲劲的人。他出身纽约市布鲁克林区,在曼哈顿的司徒佛逊高中(Stuyvesant High)时是数学神童,曾赢得西屋科学奖第一名;他是普林斯顿那一届的毕业生代表(1978),后来以罗德奖学金(Rhodes fellowship)在牛津拿到博士学位。他在1987年拿到的麦克阿瑟“天才”奖似乎已显多余。他母亲说她完全不知道儿子何以这么杰出:“我很想说这是我的功劳,其实不是……我只能说这是运气。”
兰德在纯数学圈子里,显得格外喜欢社交,最后他终于发现纯数学是“孤立、类似修道生活的领域”,于是加入比较有趣的哈佛商学院去任教,但他很快就发现自己对神经科学家弟弟的工作产生兴趣。在受到启发后,他晚上到哈佛和麻省理工的生物系进修,但白天在商学院的工作仍处理得好好的:“我几乎是在街角就把分子生物学念起来的,不过这里有很多非常好的街角可以让你私下学习。”麻省理工的怀特海德研究所就是这些街角之一,而兰德也在1989年成为该所的生物学教授。
即使在所谓的G5当中,兰德的实验室对DNA序列的贡献也是最大的。G5指基因组公共计划的五大中心——兰德的实验室、桑格中心、华盛顿大学的基因组定序中心、贝勒医学院和美国能源部在沃尔纳特克里克的实验室。他的麻省理工小组也是在促成基因组草图问世的最后冲刺阶段,大幅提高生产力的大功臣。1999年11月17日,人类基因组计划庆祝定序第十亿个碱基,那是一个G。短短四个月后,也就是2000年3月9日,T成为第二十亿个被定序的碱基。G5加足了马力。因为赛雷拉基因公司在使用公共计划的数据,这些数据总是在被发现后立即上网,现在公布的数据又多又快,可以借力使力的温特或许终于决定可以松懈一下,把赛雷拉原本预定要做的定序数量减半。
当公共与私人机构的竞赛在媒体的战场上达到高峰时,在后方,备战的焦点已逐渐转移到数学智库上,也就是隐身在密室中一排排计算机后的科学家。他们得设法解开所有这些A,T,G,C的原始序列。他们的任务主要有两项。第一,把手上许多分散的片段组合成完整的、确定的序列。大多数的部分都已经被定序了无数次,所以他们等于是要理清包含数个基因组的序列,而且得去芜存菁,直到只剩下一个标准的基因组序列。这是相当庞大的计算工作。第二,辨识最后序列中的成分,尤其是基因的位置。要确认基因组的成分(分辨这些由A,T,G,C构成的片段,哪些编码垃圾,哪些编码蛋白质),必须靠极度密集的计算机运算才能达成。
在赛雷拉基因公司负责计算机运作的人是迈尔斯(Gene Myers),这位计算机科学家是率先全力支持全基因组随机定序法的人。早在赛雷拉公司还没成立前,他和威斯康辛州马什菲尔德研究基金会(Marshfield Research Foundation)的韦伯(James Weber)就已建议公共计划采取随机定序法。因此对于迈尔斯来说,赛雷拉的成功是他的光荣,也让他获得平反。
由于先前已经建立起基因地标,因此尽管基因组序列相当庞大,比起迈尔斯在随机定序法的无地标世界的遭遇,公共计划的组合工作似乎没有那么吓人。(在最后的分析中,赛雷拉使用了公共计划供人自由取用的基因图谱信息。)事实上,公共计划正是以为可以依赖这些地标,才低估了运算上的困难,所以当赛雷拉增加计算机能力时,公共计划的注意力仍然集中在定序工作上。一直到相对后期的时候,公共计划的领导人才发现,尽管有图谱,他们仍然得解决如何去组合这个大问题,就像到圣诞夜还在努力组合新脚踏车的父亲一样。完成(以及组合好)基因组“草图”的日期已经定在6月底,但一直到5月初,公共计划仍找不到组合所有序列的方法。最后,前来解危的救星居然是加州大学圣克鲁斯分校的一位研究生。

肯特用100台计算机为公共计划组合出基因组草图。
他名叫肯特(Jim Kent),长得有点像“感恩而死”(Grateful Dead)摇滚乐团的一个成员。从进入个人计算机时代以来,他就一直在为计算机制图和动画撰写程序,但后来他决定念研究生,投身生物信息学(bioinfor-matics),亦即致力于分析DNA与蛋白质序列的新领域。有一天他在收到微软寄给Windows95程序开发人员的整整12张CD-ROM时,决定不再做商业程序设计:“我心想整个人类基因组可能只需要一张CD-ROM就够了,而且不必每3个月就更新一次。”到了5月时,他自信已经想出一个好方法,可以解开大家都在谈论的组合问题,于是他说服校方把刚为教学购置的100台个人计算机“借给”他。然后他展开为期四周的程序设计马拉松,晚上还冰敷手腕,以免白天编写大量程序代码时,手腕会变得僵硬。他的最后期限是6月26日,那也是预定宣布完成基因组草图的日期。他终于写好程序,让100台计算机开始运作,结果在6月22日,他的百台计算机大军成功解决了组合问题。赛雷拉的迈尔斯甚至到更接近底限的6月25日晚上才完成。
2000年6月26日终于来临。克林顿在白宫,布莱尔在唐宁街10号首相官邸同时宣布,人类基因组计划完成第一份草图。这场竞赛以平手收场,双方共享荣耀。至少在这天早上,对阵双方都把敌对情绪抛在脑后。克林顿宣称:“今日,我们学习上帝创造生命的语言。在获得这个深奥的新知识后,人类即将获得全新、庞大的治疗疾病的力量。”伟大的时刻搭配伟大的言辞。在面对这个被媒体喻为和阿波罗号首度登陆月球一样伟大的成就时,很难不感到光荣,即便这次成功的“官方”日期定得有点武断。其实这时定序工作根本还没完成,而且一直要到6个多月以后,基因组的正式科学报告才会问世。有人便嘲讽说,这个宣布时机不是根据人类基因组计划的时程,而是根据克林顿和布莱尔的行程制订的。

2000年6月26日:草图在握的温特(左)和柯林斯暂时放下敌对意识,跟总统一起成为瞩目焦点。

在白宫外:(左起)沃森、兰德(麻省理工怀特海德研究所)、吉布斯(Richard Gibbs,休斯敦贝勒医学院)、瓦特斯顿(圣路易华盛顿大学)和威尔逊(圣路易华盛顿大学)合影。
在白宫的大肆宣扬下,人们很容易忽略这场庆祝的对象只是人类基因组的“草图”而已,还有许多工作尚待完成。其实称得上完整并已发表的序列,也只有最小的两条染色体(第21和22号染色体)而已,何况就连它们也不敢说是百分之百完整无缺。至于其他的染色体序列,有些都是空隙。自从那场隆重的宣布后,大家的目光已经放在2003年4月的新期限上,要在这个日期前填补好这些缺口,提出完整、正确的序列。然而后来证明,有些小区域根本无法定序,而实际目标也变成找出“基本上完整”的序列:至少完成95%的序列,而且误差率在万分之一个碱基以下。
带领各国的定序中心度过最后障碍的功臣之一,是出身美国中西部、作风豪迈的威尔逊(Rick Wilson),他继瓦特斯顿之后成为华盛顿大学基因组研究中心的主任。这场游戏的名称叫做“质量控制”,每条染色体都由一位协调人负责,他们必须监督进展,确保自己负责的对象符合这个计划的整体规定。在定序过程中偶尔会有问题发生(例如一条稻米序列莫名其妙地混入要送至数据库的数据中),但筛检程序证明可以有效地排除这种污染。在我撰写本书时,人类基因组计划正朝2003年4月前完成“基本上完整”的序列前进,也是双螺旋体发表50周年。
人类基因组计划是一项了不起的科技成就。如果在1953年时有人说,整个人类基因组会在50年内定序,克里克和我一定会大笑,请他再喝一杯酒。过了20多年,首批DNA定序法终于问世时,这种怀疑似乎仍很合理。这些方法当然都是技术上的突破,但当时定序过程仍极度缓慢(即使要定序长度只有数百个碱基对的基因,都是一项重大挑战)。如今,在仅仅又过了25个年头后,我们已经在庆祝完成大约31亿个碱基对的序列了。然而我们仍然必须牢记,虽然基因组定序是惊人的成就,但它绝不只是一个科技上的里程碑而已。不论直接的政治动机为何,克林顿在白宫庆祝会上说得很对:我们手中可能已经握有对抗疾病的强大新武器。而且,我们甚至可能对生物的组成与运作,以及我们和其他物种之间的差异有全新的了解,亦即洞察我们之所以为人的道理。