我们认为自己与猿类的区别在于我们拥有思考的能力。但是我们不曾记得,这种能力只类似于一岁孩童的行走能力。我们的确在思考,但是却思考得如此糟糕,以至于我时常感觉,也许我们不去思考反而更好。
5.1 超越已有的信息
我们人类拥有一种无与伦比的能力,可以推断隐藏物体或尚未发生事件的特征。这种“超越感官信息”的能力是知觉过程的自然扩展。有几种近乎自动化的基本认知能力可以支撑我们的这种判断才能:判断客体或事件彼此间相似性;识别出经历过的情境或见过的人;提取已辨识客体或情境的额外信息以及“洞察”事件之间因果联系。这些认知过程的发生几乎不需要意识努力,它们被牢牢地“捆绑”进我们的大脑,以至于在健康成年人的一生中都不会有太多的改变(Kahneman,2003)。
本章,我们将用更多的信息加工模型来介绍心理过程,这些过程通常将某些特殊线索联系起来,从而促使人们做出判断(第3章透镜模型中公式右边所介绍的线索利用过程)。依据Amos Tversky和Daniel Kahneman(1974)的见解,我们认为对潜在认知判断过程的一种较好解释是,我们的长时记忆中贮存着一个装有“心理启发式”的认知工具箱。用启发式来解决问题效率较高,但并不精确——也就是说,它只对频率、概率和数量进行粗略的估计。“启发式”这个术语来自于数学和计算机科学,这些学科区分了算法和启发式。算法(algorithms,通常效率较低)指的是针对某类特殊问题的解决方案;而启发式(heuristics)则指的是用一种更有效率的方法解决同样问题,但通常会得到有偏结果。这些启发式程序通常以简单的心理能力为基础,如我们的相似性原则、记忆以及因果判断过程。
上述认知工具是在人类毕生的经验中获得的。它们告诉我们应该在环境中选择什么样的信息,以及如何整合不同来源的信息以推断出无法直接知觉的事件特征。我们通过一次次的试错试验,通过家庭和同伴的影响,以及通过有意的传授等途径习得这些认知工具。有些认知工具是需要意识控制并且要经过深思熟虑的(例如,我们在学校里学过的除法运算规则,或者决定是否在扑克牌游戏中下赌注的推理过程),而另一些却是自动化的、内隐的(例如,我们在判断一个人是否撒谎,或者决定菜里该放多少盐时所依赖的一些无意识习惯)。
每当我们碰到一个需要做出判断的情境时,我们就从认知工具箱中挑一个合适的工具来帮助我们做出恰当的判断。对于很多日常判断情境来说,我们通常使用启发式策略,因为它需要耗费的心理努力较少,并且在绝大部分情况下能够得到较好的结果。正如Tversky和Kahneman对认知启发式所做的经典描述那样:“总的来说,这些启发式是非常有用的,只不过它们有时候会造成严重的系统性错误”(p.1124)。
在本章,我们将关注两种主要的判断启发式,它们均依赖于我们那与生俱来的记忆提取和相似性评估等基本能力。我们将列举一些实例,说明何时何地会用到这些判断启发式,同时指出这些判断将会带来何种系统性的评估偏差和预测偏差。从根本上而言,当要求我们对难以估计的频率、数量或概率进行判断时,我们会将原来的评估方法替换成一种更简易更自动化的评估方法(例如,依赖于记忆提取的简易程度或者客体间的相似程度来进行估计)。
5.2 估计频率和概率
我们拥有与生俱来的估计频率的能力。当我们经历外部事件时,知觉和记忆系统会自动记录这些事件发生的频率。当然,很多信息毫无用处,例如,我们阅读过的文本中某个字母的出现频率、上班沿途路过的快餐店的数量、上学期校园里放映过的电影数量,等等。但是,有些信息却可能对生存至关重要,至少在某些原始环境中(这些环境通常对人类的进化意义非凡),例如,注意到森林中不同地方的可食植物的数量、水塘旁遭遇过的食肉动物的数量或竞争部落中敌人的数量等都将是非常必要的。
对于基于记忆做出的频率估计,我们能够构建一个将客观数量对应于主观数量的心理物理函数。在客观频率较低的一端,主观频率倾向于高估。随着被评估事件客观频率的增加,主观估计误差则朝着低估方向发展。(这种先高估再低估的模式叫做回归,类似于统计回归曲线。)图5.1显示的是人们根据记忆对各种致命事件(如心脏病、车祸、自杀等等)发生频率的估计结果。在数以百计的评估情境中都能观察到类似的心理物理曲线,这证明我们具有某些普遍存在的频率估计习惯。
当对事件进行即时评估而非通过记忆提取的时候,心理物理评估曲线会与上面的有所不同。在即时条件下,小数量的客观频率(1~5个/次事件)能够被准确估计。事实上,早期的经验论哲学家们曾做过一些关于短时记忆的研究,在实验中他们将一把鹅卵石撒到桌子上,然后迅速盖住,要求参加实验的人估计鹅卵石的数量。当不超过5个时,人们能够精确地估计,因此“5”也被称为“理解范围”。然而,当要求人们估计的项目数量超过10个时,低估倾向开始出现,正如以记忆为基础的函数那样。所以,当项目数超过7个时(“7”被认为是短时的、有意识的工作记忆的容量),人们就会用一种更审慎的评估策略来进行频率判断。
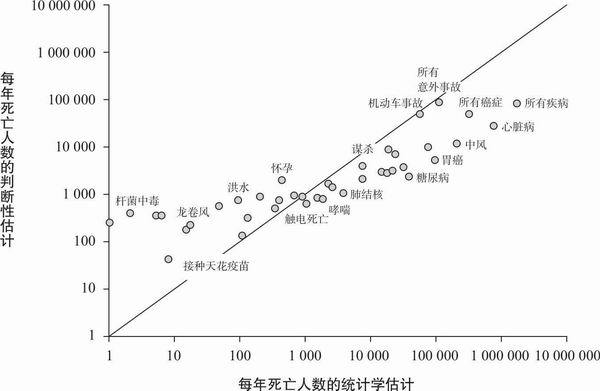
图5.1 致命事件的频率估计曲线(备注:为使关系更加明显,图中的坐标轴进行过对数化处理,但是其中高估低频率事件和低估高频率事件的基本模式仍然清晰可见。)
5.3 记忆可得性
我们做出的许多判断都是以记忆为基础的,即在做判断时虽然手头上没有必要的信息作为依据,但是我们可以利用过去习得并存储于长时记忆中的相关信息。这种简单的联想思维被称为可得性启发式(availability heuristic),我们依赖于简便的检索提取来应对名目繁多的判断任务。
有时我们做出的判断全部取决于在头脑中提取信息的便捷程度(或流畅程度)。比如我们正在计划一次航空旅行,这时飞机撞击世贸大楼的惨象很快闯进了我们的脑海,于是我们就改变想法了。2001年“9·11”恐怖袭击后的第一个月内旅客乘坐飞机的数量下降了20%(Gigerenzer,2006)。此外,当没有其他信息可用时,人们甚至依赖于简单的可识别性来估计数量(里诺、内华达、埃森和德国哪个地区人口最多?)和价值(可口可乐和伯克希尔-哈撒韦,这两支股票哪支投资收益更好?)。当我们使用更多的意识努力从记忆中提取数据来帮助判断时,我们也会依赖于提取的流畅程度。Norbert Schwarz和同事们曾经要求大学生对他们自身的果断性(或犹疑性)进行评估(Schwarz et al.,1991)。但是在评估之前他们需要回忆出能够表现果断性的事例。一半的被试需要回忆起6个事例,这是相对容易(流畅)的任务;另一半被试需要回忆起12个事例,这是相对困难(不流畅)的任务。结果发现,提取的流畅性是一个中介因素:自我评估的结果与提取任务的流畅性水平是相对应的,回忆事例的数量与自我评估呈现负相关。这种效应在判断心脏疾病的危险性和推断消费者的个人偏好任务中也得到了证实(流畅性也是判断喜好的一个基础;Schwarz,2004)。
有时我们会依赖于即刻闯入脑海中的事例的数量进行判断。离婚率在增长吗?当我们要回答这个问题时,几个熟人离婚的例子瞬间闪入意识,然后我们做出了离婚率很高而且在一直增长这样的判断。当我们回答自杀和谋杀哪个对大学生更具有威胁这一问题时,更多的缘于谋杀的死亡事例闯入我们的脑海,所以,我们支持在校园警力上而不是在自杀求助热线上增加投资。
可得性启发式的过程可以被分解成几个子过程或子程序(见图5.2):(1)在长时记忆中获取或存储相关信息;(2)保持存储信息,同时伴随一些遗忘;(3)情境再认,包含与决策相关的信息;(4)探测记忆或提供记忆线索以找到相关信息;(5)提取或激活与记忆探测相匹配的项目; (6)评估提取的便捷性(可能基于回忆的数量、速度或信息的主观生动性);(7)基于感知到的提取便捷性来估计频率和概率。
在可得性启发式过程中存在着几个关键点,如果这些地方出现偏差,则会影响到最后的判断结果。首先,存储于长时记忆中的事件样本(被记住的信息)可能出现偏差,正如上面有关自杀和谋杀的例子;其次,作为提取基石的记忆线索可能出现偏差,这样一来,即使总体是有代表性的,也会生成有偏的样本。最后,记忆中的事件可能具有不同的凸显性或生动性,以至于某些更凸显的事件主导着提取便捷性。这些因素单独或共同存在,都有可能会使以记忆为基础的判断结果产生系统性偏差。
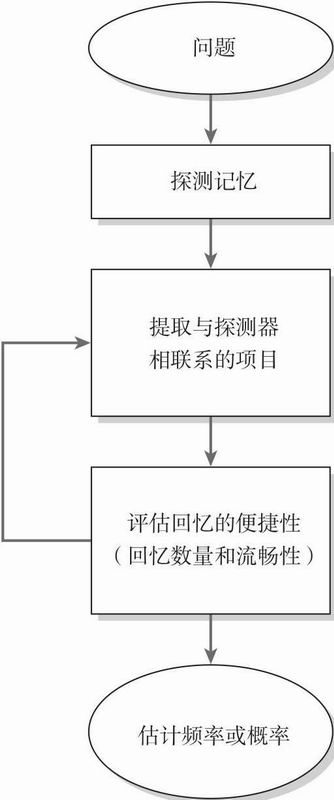
图5.2 可得性启发式判断的流程图;箭头代表子阶段在总过程中的顺序
5.4 记忆中的有偏样本
统计数据表明,死于自杀的人比死于谋杀的人要多,而且,由于人们倾向于把无法确定的案例看成“意外死亡”,因此自杀和谋杀的实际比率很可能被低估了。单人驾驶时出现的车祸事故中有多少人实际上是死于自杀呢?这些事故中有很多通常被认为是由酒精导致的,即使那些司机可能是为了自杀而喝酒壮胆。然而,大部分人认为谋杀更常见。为什么呢?最简单的解释就是谋杀得到公众更多的关注。无名小卒的自杀案件很少见诸于报端,但是无论受害者的身份如何,对谋杀案的报道却比较常见。这一解释已经在Barbara和Paul Slovic的研究中得到验证(见图5.1),研究发现人们对各种死因的估计与它们被报道的频率有正相关,并且这种关系独立于实际的发生频率。所以,由飞机事故、鲨鱼袭击、龙卷风、恐怖袭击引起的以及其他得到媒体大量报道的死亡被高估了,而诸如中风、胃癌、家务事故和铅涂料中毒之类的死亡则被低估了。通过体验而获得的信息(存储于记忆中以便于判断之用)在其获得之初就产生了偏差。
犯罪事件中由精神病患者引发的比例占多少?由非裔美国人引发的呢?每当一个有过精神病史的人犯下罪行时,特别是暴力罪行,此人曾经进过精神病院的历史就会被新闻提及。但是,新闻从不会报道某犯人没有进过精神病院,“从来没进过精神病院的史密斯被指控犯罪……”,类似的报道是绝不可能出现的。针对媒体报道的系统研究显示,少数族裔的罪犯受到过度的新闻报道,尤其是暴力犯罪者(Franklin Gilliam,Shanto Iyengar和他们的同事将此描述为“当地新闻眼中暴力恐怖的世界”)。Wendi Walsh、Mahzarin Banaji和Tony Greenwald(引自Park和Banaji,2000)的实验证明了这种记忆偏差的存在。他们请大学生在一份名单中圈出他们所知道的罪犯的名字,而实际上名单里的名字没有一个是真正的罪犯。但是结果却发现,大学生们“记得”的非裔美国人的名字(如“Tyrone Washington”等)几乎是其它族裔人名(如“Adam McCarthy”、“Wayne Chan”等)的两倍。即使研究人员提醒实验参与者“种族主义者认出的黑人名字要多于白人名字;请不要利用名字的种族性来做出判断”,这种记忆偏差仍然存在。
社会学家Barry Glassner(1999)记录过很多偏差,这些偏差源自于那些“流血事件必上头条”的新闻报道,也有的是被特殊利益集团所引导,从而控制了公众对犯罪、疾病及其他危害的恐惧情绪。50个州7年时间里公路暴躁症案例上升了大约700起,这是否意味着公路暴躁症成为“流行病”?孩子的日托管理正在(或曾经)经历一场撒旦崇拜的危机,这可信吗?1994年,某研究团队在美国政府的资助下历时4年花费750 000美元,得到的结论是,有关日托中心撒旦阴谋的神话完全是子虚乌有(Goodman,Qin,Bottoms & Shaver,1994;Nathan & Snedeker,1995)。携带自动武器的高中生真的是青少年安全问题的首要关注对象吗?(1999年,大约2 000名学龄孩子被谋杀;只有26人死于学校,其中的14人死于科罗拉多州利托顿哥伦比亚高中的一场悲惨事故。)人类学家Douglas(Douglas & Wildavsky,1982)指出,每一种文化都有很多被夸大的恐惧,其中有许多是被特殊利益团体所强化的,或者是用来捍卫其意识形态的。例如,欧洲的“不洁之水”在14世纪就已经是一个危害了,但仅仅是在犹太人被指控在井中投毒之后,居民们才开始把它当成一个重要问题来对待(p.7)。
但是,最初的新闻报道并非总是动机不良的。我们都倾向于把反常的特征(不常发生的)进行编码和表述,比如住过精神病院的人比没住过的要少、在美国黑人比白人要少、左利手的人比右利手的人要少。结果就导致这些独特的特征在整个人群中的频率被高估。绝大部分接受福利救济的人并不是“福利女王”(滥用福利制度的人),但是这却导致公众把更多的注意转向那些是“福利女王”的人,从而进一步导致对“福利女王”人数的高估。
进行概括化时,只发生一次的事件是非常不可靠的证据,特别是当该事件并不典型时。然而,这样的概括化却经常发生。而且事件越凸显,发生的可能性越大。例如,一个非犹太人认为自己被一个或两个犹太商人欺骗了,那么她很容易将这种消极评价概括到整个犹太民族:
一个年轻女士跟我说:“与毛皮商打交道时我经历了最可怕的事情;他们抢劫我,烧掉了我托他们照管的毛皮。他们全部是犹太人。”但是,为什么她选择去仇恨犹太人而不是毛皮商呢?(Sartre,1948,pp.11-12)
Richard Nisbett和Lee Ross(1980)指出,理性的演绎逻辑是一个具体化的过程,即从一般到特殊(“所有的人都难免一死,因此罗宾·道斯难免一死”);而与之相比,归纳逻辑是一个概括化的过程,即从特殊到一般(“这个犹太商人是不诚实的,因此所有的犹太商人都是不诚实的”)。相对而言,归纳逻辑的可信度会下降。但是我们的所作所为正好与它们的可信度相反:过分归纳而演绎不足。
5.5 记忆抽样偏差
显然,如果存储在记忆中的信息样本有偏差(也许因为主流媒体的过滤作用),那么随后以此为基础的判断也将出现偏差。不过记忆过程的其他方面也能引起同样的系统偏差。
有多少6个字母的英文单词以如下形式构成?
_ _ _ _ n _?不多吧?
有多少6个字母的单词以如下形式构成?
_ _ _ ing?更多吗?
当Tversky和Kahneman(1974)要求人们做上述预测时,人们认为以-ing结尾的6个字母的单词比第5个位置上是n的6个字母的单词更多。(第5个位置上是n的6字母单词当然比以-ing结尾的6个字母的单词多。逻辑上也是如此,因为所有以-ing结尾的6个字母的单词的第5个位置上必然是n,而除了以-ing结尾的6个字母的单词之外还有其他形式的单词第5个位置上是n——比如,absent。)当然,想起以-ing结尾的6个字母的单词要容易得多——比如,ending;查阅字母表时也更容易找到它们:aiming,boring,caring,等等。但是想起第5个位置上是n的6个字母的单词就要难得多(除非-ing突然进入脑海)。我们甚至可以从直觉上评估出生成这两种不同形式的6字母单词的困难程度。
人们相信,自己在超市结账时特别容易排到行进缓慢的结账队伍中,自己没带雨伞时更有可能下雨,运动员在被体育解说员赞赏之后就犯错误是因为解说员的乌鸦嘴。为什么呢?鉴于这些事件之间并没有逻辑联系,如此这般的迷信信念只能是建立在对经验的总结之上。但是那些总结只是被记住的经验,并且在结账队伍里躁动不安、被淋成落汤鸡、走霉运的经历以及其它巧合事件在记忆里特别容易提取;我们认为其它记忆也是存在的,只是不易被记起。事实上,人们普遍信仰包括透视力在内的灵力,这也是由可提取性不同以及各种巧合记忆的偏差造成的。例如,某天突然想起多年未见的某个人,恰巧那天接到了他的电话。诺贝尔获奖者Luis Alvarez(1965)针对这种个人经历进行了一项分析,结果显示任何人在任何地方都不可避免地要碰到一些巧合事件。虽然巧合事件在一个人的经历中是少见的,但是我们必须记住,它们在一大群人的经历中是普遍存在的(Diaconis & Mosteller,1989)。
Robert Reyes、William Thompson和Gordon Bower(1980)通过实验证明了提取可得性偏差如何影响司法裁决。他们在一个酒后驾驶的案例中操纵了材料的呈现方式,使起诉方的证据或者辩护方的证据看起来更生动或更容易记住。该案例的裁决取决于被告撞向垃圾车时是否喝醉酒。辩护方的免罪证据——因为垃圾车被涂成灰色所以很难看到——用两种版本呈现,一种是描述贫乏、容易遗忘的版本(“垃圾车司机在盘问中供认他的车由于涂成灰色所以在晚上很难看到。”),另一种是描述生动、容易记忆的版本(“垃圾车司机供认他的车由于涂成灰色所以在晚上很难看到。他说车之所以涂成灰色是因为‘它是一辆装垃圾的车,灰色能藏住污垢。你想怎么样?难道我应该涂成粉红色?’”)。起诉方的定罪证据也进行了同样的操纵——描述贫乏的版本(“被告离开聚会往门口走时步履蹒跚地撞向一张餐桌,把一个碗撞到了地上。”),或者描述生动容易记忆的版本(“被告离开聚会往门口走时步履蹒跚地撞向一张餐桌,把一个盛有绿色鳄梨酱汁的碗撞到了地上,四散的鳄梨酱溅泼在昂贵的白色粗毛地毯上。”)。案件中使用生动证据来进行描述的一方可以靠愚弄陪审员而在裁决中占尽优势;当在听取证词48小时后才进行裁决时,产生了更加显著的生动性效应,因为此时记忆的优势会更重要。
律师们使用示意证据给陪审员留下深刻印象正是利用了可得性偏差。律师马尔文·贝利曾受理一起个人伤害案件,审判过程中他始终将一个用包肉纸裹着的、形状极似当事人截肢的包裹放在身前的桌子上,并使它处于陪审团的视野范围内。他能想出这种办法,也难怪会赢得创纪录的奖项了。
事件激发的情绪对记忆有长远的影响,进而也会影响到根据记忆所做出的判断:当我们处于一种特定的情绪状态时,会倾向于记住与情绪状态主题一致的事件。Eric Johnson和Amos Tversky(1983)的一项实验室实验证明了情绪对风险决策能够产生影响。他们要求实验参与者评价风险和事故的等级(同图5.1中的相似)。一些实验参与者在休息室等候的时候会听到背景广播里的新闻报道,以引发他们的焦虑或者忧虑情绪(报道事件为一个与实验参与者情况相似的人的死亡)。结果发现,与那些听到高兴或中性新闻的参与者相比,引发负性情绪的参与者给出了更高等级的风险评估。
William Wright和Gordon Bower(1992)使用更加强烈的情绪操纵手法重复并拓展了上述实验。他们使用催眠手段将实验参与者置于一种高兴、中性或悲伤的情绪中。由此表现出来的情绪一致性效应更加明显,即参与者认为与其情绪一致性的事件非常可能发生,而与其情绪不一致的事件不可能发生(图5.3)。所以,通过催眠产生高兴情绪的参与者认为“幸事”(如世界和平,治愈癌症疗法的新发现)的发生概率高,“灾难”(如在车祸中受伤,大规模核电站事故)的发生概率低。
类似的例子不胜枚举。原则很简单,我们经历过某类现象(人、物或事件)后,再想起时,往往更容易记住那些具有显著特征的。进而,如果让我们估计某群体里具有显著特征的个体比例,那么我们倾向于高估它。当我们仔细计算了(比如用机械计量器)类似群体中具有该特征的成员数目时,会发现我们的估计远远超过了它。记忆的选择性提取能够引发较大的估计误差,造成对重大社会问题的错误理解,最终导致严重的决策偏差(诸如投票人群、陪审员和政策制定者所做出的决策)。
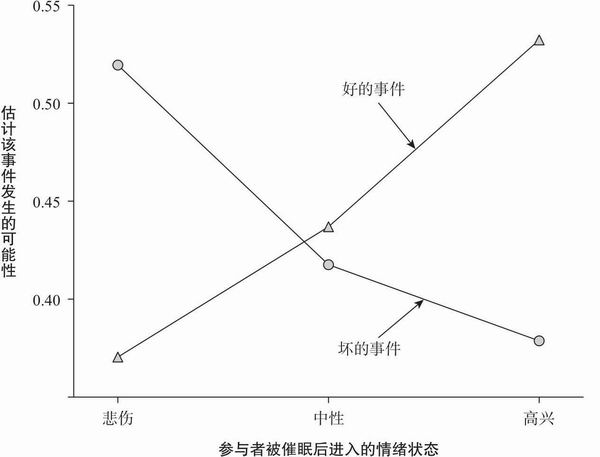
图5.3 情绪操纵对概率估计的效应(基于Wright和Bower的实验结果,1992)
5.6 想象可得性
对孩子来说,以下两个事件哪个更具威胁性:在家里藏一支枪还是建一个游泳池?即使你无法想起任何一个先例,也总是很容易就想象到孩子在家里翻出枪然后伤害到自己的画面,而不可能第一直觉是一具漂浮在游泳池里的尸体。或者请想象一个由10人组成的小组,然后凭直觉估计从小组中选出2人组成一组,会有多少种组合方法?之后再估计选出8人组成一组,有多少种组合。人们通常对前者的估计大于后者,因为人们会认为从10人组中选出2个人成组比选出8个人成组要简单得多,而且做出这种估计并不需要在心里罗列出所有的组合,仅凭直觉我们就已经形成这一印象,人们会感觉两两成对要比8人成组更容易实现。
实际上,8人成组的数目与2人成组的数目完全相同,纯逻辑运算可以证实这样的结果。每一次从10人组中选出2个人成组,都会留下另外8个人形成另一个组。所以2人组与8人组是一一对应的关系;甚至无须任何公式即可推出它们数目相等的结论。很明显,“想象”在判断可能性时存在着缺陷。
在上述事例中,想象的可得性影响到我们对频率的估计。如同直接体验或间接体验的可得性一样,“想象”的问题在于其可得性也受到实际频率之外的因素影响。某些类型的思考明显比其他类型的简单,某些想法也比其他的想法更容易闯入脑海。而且这种区别不完全依赖于过去的经验。(试问有多少人过去体验过分2人组或8人组的问题?)想象的便利性使我们的频率估计产生偏差,进而影响以这些频率为基础的概率判断。
5.7 从可得性到概率和因果关系
人们在评估集合(集合中各元素彼此独立、互补,且穷尽了所有元素)中每个元素发生的频率或概率时,往往出现一种可得性效应,这个概念在理论上很重要。Tversky和Kahneman以及他们的同事Donald Redelmeier和Varda Liberman请52名医生根据下面的描述估计住院病人出现不同结果的概率:
● 住院治疗期间死亡
● 活着出院,但是一年内死亡
● 活了1~10年
● 活了10年以上
因为这四种情况穷尽了所有可能的结果,所以它们的概率之和应该为1。而这些事件被单独评估时(每个医生只评估其中的一种)其概率之和为1.64,如果医生们果真遵循概率论的法则使相互穷尽的事件集合的总概率为1的话,那么1.64显然太高了。医生们的这种行为与棒球运动员尤吉·贝拉(因总是说错话而出名)一样,后者曾经对记者说:“如果我们有50%的机会再次赢得美国联盟的冠军,那么也不该忘记仍有75%的可能输掉比赛。”Tversky和同事们将这种概率的次可加性(subadditivity)解释为医生只是凭借自己的想象评估每个事件的发生概率。互补性子事件的描述为每一种特定结果提供了有效线索。例如,“死于住院治疗期间”的描述使医生想到一些“死在医院中”的具体生动的例子(手术并发症、麻醉事故、术后感染等等),而其暗含的反向结果(“住院治疗期间未死亡”)却没有给想象提供有效的线索或联系。Tversky和他的学生Derek Koehler(1994)在其他领域也发现频率估计的次可加性模式,如汽车故障修理、天气预报、体育结果预测等等。
本书的作者之一(道斯)对个人事件判断中存在次可加性很感兴趣,这源于他曾经收到的一份报告“外星人绑架所带来的创伤后应激是严重的心理健康问题”。报告还声称至少2%的美国人受到该问题的困扰(暗示在国家有关政策中该问题应排在“无家可归”之前)。这份报告的作者(Hopkins & Jacobs,1992)用近期Roper Poll民意测验中一道题目的肯定作答率来支持以上结论,该题目是:“你是否有过下述情形:醒来后浑身发麻,感觉屋子里有陌生人或别的什么东西?”
道斯和同事Matthew Mulford(Mulford & Dawes,1999)对Hopkins和Jacobs的荒谬结论进行了后续研究。他们请一组参与者回答同样的问题,令人吃惊的是,被问及这种古怪体验时40%的人回答至少发生过一次。另外的对照组参与者(随机分配)需要回答的问题只是“醒来后浑身发麻”(没有被问及“陌生人存在的感觉”),而这一次,只有14%的人做出了肯定回答。显然,提及“陌生人或别的什么东西”的详细描述使人“回忆起那些原本可能从大脑中溜走的事例”(引自Tversky和Koehler[1994]对潜意识过程的描述)。
另外,Michael Ross和他的学生Fiore Sicoley(1979)也研究了判断的次可加性。他们请“团队”里的成员估计自己为团队付出的贡献。配偶、师徒和篮球运动员都高估了他们的个人贡献:每一个组合中个人贡献之和都远远超过最大值100%。最有趣的是在两类自我夸大上——积极贡献以及消极贡献(“引发争吵”,“分析数据时犯错”,“犯规”)这种高估均会发生。这种高估现象的潜在认知过程可能存在于记忆提取和生成想象之中,其中记忆提取无疑是解释之一:后续研究显示次可加性评估与受试者回忆具体贡献的能力高度相关,这暗示记忆可得性也是该认知过程的一部分。
Tversky和Koehler(1994)认为将整体事件(如汽车无法发动、病人死亡、经济衰退等)的各种子成分分开再描述是对整体事件的“解压缩”(也见Rottenstreich & Tversky,1997)。大部分研究发现,次可加性描述的是整体事件与其分离解压后子成分之间的关系(“汽车无法发动”与“没油了,没电了,打不着火了等”)。不过,也有超可加性(superadditivity)的例子存在,即在概率估计上整体要大于部分之和。这似乎也是由潜在的可得性加工过程的本质导致的:当解压后的成分难以考虑、想象和回忆时,它们被判断为不可能发生,从而使整体-部分的关系发生逆转,整体事件发生的概率比其各部分发生的概率之和要高。Laura Macchi、Daniel Osherson和David Krantz为概率估计中的超可加性提供了解释,即“反向提取困难效应”。在他们的研究中,要求大学生判断难解的科学问题和百科知识方面的问题(汽油的熔点比酒精高吗?泰国的人口出生率比缅甸低吗?)。结果发现,解压后子成分的概率之和小于1。
次可加性、超可加性的发现以及其他针对提取流畅性的精巧论证,都证实了可得性在潜在认知过程中的显著作用。这一发现最重要的现实意义是,帮助我们理解公民(与他们的政治领导人)在制定公共资源的分配方案时应该如何思考和决策。被孤立的高中生、不诚实的福利受惠者、有恋童癖的牧师、有缺陷的航线、激进的恐怖主义分子以及许多其他的范例,所有这些因素在公众想象里的认知可得性会对我们如何分配税收和如何制定相关法律产生重大的影响(见John Kingdon的经典之作——《议案、备择及公共政策》(1984),关于政治议案的开拓性研究)。
5.8 基于相似性的判断:老一套
第二个利用启发式判断数量、频率和概率的基本认知过程是相似性。有许多判断任务涉及将某客体或某事件归类到合适的范畴中。比如说,当我们想知道持续两周的咽喉痛究竟只是轻微感冒、过敏症状,还是严重的脓毒性咽喉炎时;当我们在餐馆的菜单上找哪些菜低盐低脂时;当我们想知道新同事是行为主义者、运动狂、忧郁者还是面目一新的天主教徒时。
请思考下面的社会成员分类判断任务:
佩内罗珀是一个大学生,朋友们形容她稍微有些不切实际、情绪化和敏感化。她游遍了整个欧洲,能说一口流利的法语和意大利语。她目前还不确定毕业后的职业发展方向,但是却已经证明过自己高水平的才能,并且多次获得书法比赛的奖项。她在男朋友过生日时写了首十四行诗作为礼物。你认为佩内罗珀的主修专业是什么?
● 心理学
● 艺术史
大部分人按照我们的诱导,相当肯定地认为佩内罗珀是一个艺术史学生。她似乎恰好符合我们概念中艺术史学生的特点。但是现在请思考下面的问题:假设你在一所大学的学生名单中随机挑选一个名字并查看其主修专业,那么上面问题中所涉及的两个专业哪个更流行?哪个不太流行?你随机选出来的学生主修心理专业的概率有多大?而主修艺术史专业的概率又有多大?(最近一项统计数据显示,在一所人数接近18 000的公立大学中,大约2 300名学生主修心理学而仅有15名主修艺术史;心理学专业在大学本科生中的基准概率约为0.13,即随机挑选一个学生其主修心理专业的概率为13%,而艺术史专业的基准概率是0.0008,两者比率为150比1![若仅限于女性的话,该比率为140比1])。许多人在明确了这些问题之后改变了最初的选择。他们意识到无论“人格描写”如何,那个人是(从18 000个人中挑出的)15个艺术史学生之一的概率总是非常低的。而且,一些受试者为他们最初的回答感到非常难堪。个别人甚至恼怒自己被一则听起来非常符合主修“极端人文”专业的描述给“骗”了——他们意识到自己不能仅凭简单的信息和艺术史学生非常小的基准概率就做出如此判断。
这个例子说明在分类判断任务中存在一种普遍倾向,即依据我们对类别的概念与待归类客体、情境或事件印象的相似性来做出判断。与基于可得性的判断一样,相似性自动地发生在判断过程并自发地主导判断任务。依赖相似性判断的主要行为特征是人们在情境中没有抓住重要的统计或逻辑结构,并且忽略了一些相关信息(例如,背景、基准概率,如佩内罗珀问题中大学各专业的总人数)。
佩内罗珀问题直观地证明我们在判断时忽略了情境中的关键要素。让我们再看一个错误更明显的例子。Tversky和Kahneman(1974)要求被试依据简短的人格描述来判断一些人从事某类职业的概率。比如,某人被描述成“不善社交,厌烦政治,在业余时间喜欢到他的船上做点事”,听起来像一个工程师。此外,被试被明确告知了基准概率数据:此人要么是工程师要么是律师,他是从一个大多数人(70%)是工程师或大多数人(70%)是律师的群体中随机挑选出来的。实验结果表明,人格描述的信息以绝对优势压倒了基准概率信息。无论这个人是来自于70%工程师的群体还是70%律师的群体,对其从事某类职业的概率判断总是相同的。即使是平淡的无任何有效信息的人格描述(“有一个老婆和两个孩子,事业上有成功的潜力,深受周围朋友的喜爱”),也被判断成50%的可能性是律师或工程师,完全忽视了基准概率的作用。只有当完全没有描述信息时,被试才能正确地判断来自70%工程师30%律师群体的人有0.70的可能是工程师(或者来自30%工程师70%律师群体的人有0.30的可能是工程师)。
很明显,人们完全依赖于自己对职业类别的刻板印象与对某人背景只言片语的描述来做出判断。当同一组被试评估职业类别与背景描述的“相似性”时,他们的估计与之前的概率判断毫无差异——相似性-概率之间的相关高达0.95。即使人们意识到所使用的描述性信息是不可靠的、不完整的、非预测性时,这种对相似性的过度依赖依然存在。
人们在基于相似性做判断时不仅仅只忽略基准概率信息。请思考另外一个例子,Tversky和Kahneman(1983)请大学生做如下任务:
琳达,31岁,单身,说话率直,性格开朗,主修哲学专业。学生时代关注歧视和社会公平问题,参加过反核武器示威活动。请按照概率高低(从高到低)排列以下项目:
● 琳达是小学老师。
● 琳达在书店工作,上瑜伽课。
● 琳达积极参加女权运动。
● 琳达是从事精神病治疗的社会工作者。
● 琳达是妇女选举委员会成员。
● 琳达是一位银行出纳员。
● 琳达是一位保险推销员。
● 琳达是一位积极参加女权运动的银行出纳员。
86%的大学生认为,“琳达是一位银行出纳员并积极参加女权运动”的概率比“琳达是一位银行出纳员”高。理由呢?基于琳达的信息,我们很容易想象出她是一名女权主义的银行出纳员,而很难想象她仅是一名普通的银行出纳员,尽管对她的描述中并没有直接提到女权主义。甚至当银行出纳员的项目被改成“琳达是一位银行出纳员,她可能积极参与女权主义运动,也可能不”时,另外75名被试中仍有57%的学生认为“琳达是一位积极参加女权运动的银行出纳员”的概率更高。
这个例子中的逻辑错误是忽视了“银行出纳员”和“女权主义银行出纳员”之间的从属关系。女权主义银行出纳员是银行出纳员的一个子集,但是肯定还有其他类型的银行出纳员:“传统女性角色”的银行出纳员、信奉基督的银行出纳员、无政府主义的银行出纳员等等。这些子集之间的关系也许并不明朗,但是有一点是肯定的,若定义所有的人都是银行出纳员而且必定存在一些不是女权主义的银行出纳员。所以,怎么可能“琳达是一位女权主义的银行出纳员”比“琳达是一位银行出纳员”的概率更大呢?很明显后者的外延更广甚至包含前者。因此,这样的回答在逻辑上是不可能的。但是人们(比如我们)判断女权主义银行出纳员比单纯的银行出纳员概率更大,主要是因为他们“忽视”了判断任务中的逻辑结构,并且过度依赖于描述,依赖于我们关于社会分类刻板印象之间的相似性(相似性-概率相关再一次高达0.95)。
多数人都熟悉韦恩图(19世纪的数学家和逻辑学家约翰·韦恩发明创造的,他还在“The Logic of Chance”上发表过论文,韦恩图用交叉的圆圈来代表不同分类的关系)。每个圆覆盖的区域代表某结果属于该集合的概率,各圆重叠的部分代表某结果属于对应的复合事件的概率。琳达问题的韦恩图明确表明,她是一位女权主义银行出纳员的概率不可能比她是银行出纳员(包括各种类型)的概率高(见图5.4)。
Tversky和Kahneman(1974)将这种错误叫做错觉,因为它像许多常见的视错觉一样,即使我们理智上承认它是错误的,但却仍然坚持己见。Steven Pinker(1997)曾说,一名学生在面对一系列这样的错觉时“为人类感到羞愧”(p.344)。进化生物学家Stephen J.Gould(1991)表达了我们大多数人都体验到的直觉冲突:“我知道出现在交集处的可能性极小,但是我脑子里一直有个小人在上蹿下跳地大喊大叫——‘仔细阅读那段描述,她不可能只是一位银行出纳员’” (p.469)。他总结说:“我们的思维不是按照概率法则运作的(不管什么理由)。”我们的思维似乎是按照基本的相似感觉运作的,实验被试对相似性的评估与对概率的评估(将被描述的人归类到某刻板类别中的概率)之间完美的相关证明了这一点。

图5.4 用韦恩图表示琳达问题中隐含的基本逻辑关系
5.9 代表性思维
上述实例主要证明:(1)分类判断任务通常以判断对象的特征与原型的代表性或相似性程度为基础;(2)代表性并没有反映实际的变化;(3)估计的概率或者判断的信心与相似性有关而不一定与判断情境的深层结构有关。在佩内罗珀问题和律师-工程师问题中,人们似乎忘记了专业或职业的基准概率背景;在琳达问题中,人们忽略了银行出纳员和女权主义的银行出纳员两个集合间的逻辑关系。图5.5对基于相似性的启发式判断过程进行了总结。
我们发现早期研究非常确信人们在多数概率判断任务中依赖于(甚至过度依赖)相似性,这也许是因为我们在解决原始问题时的自我反思过程与代表性-相似性的解释模型完全一致。一个更富争议性的话题是这些判断中表现出来的非理性。Tversky和Kahneman(1974)将教科书中的概率问题具体化并设计成实验中的两难困境。被试对这些问题的回答通常是错误的。但是对类似问题的行为反应却并不完全呈现出跨研究的一致性,错误也并不总是如上述例子那样极端,即使被试给出明显错误的答案也是有理有据的(Birnbaum,1983;Koehler,1996)。因此,我们的重点将转到另一个话题,即这些结果是否证明人们是非理性的,从而导致了第8章中将会提到的各种适应不良的日常判断。
当代心理学家假设,诸如银行出纳员、女权主义者、微型计算机和臭鼬等各种事物分类的概念在我们头脑中是以属性列表的方式被表征的,我们认为这些属性正是对这些实体的定义和表征。这种概念表征方式非常有用,但也有些虚构化和简单化。所以,如果我们问某个人“鸟”所代表的意思,通常会得到一系列与“鸟”这个标签相关的特征。如果某物是鸟的话,它就应该会飞、有羽毛、下蛋、吃虫子等等;如果某人是“艺术史学生”的话,就应该包含敏感、情绪化、富有文化底蕴、女性、文雅等特征。我们在思考大部分日常概念时往往考虑的是关联性、典型性和相关性属性,而不仅仅是分类的本质定义。我们还经常用一些明知不适用所有成员的特性来代表分类(如鸟能“飞”,艺术史学生“富于文化底蕴”)。此外,当我们试图回答“它是什么意思?”时,会借用进入思维的某些成员的特征来考虑某个类别的概念。所以,记忆可得性即使在类别概念表征中也有一定影响。
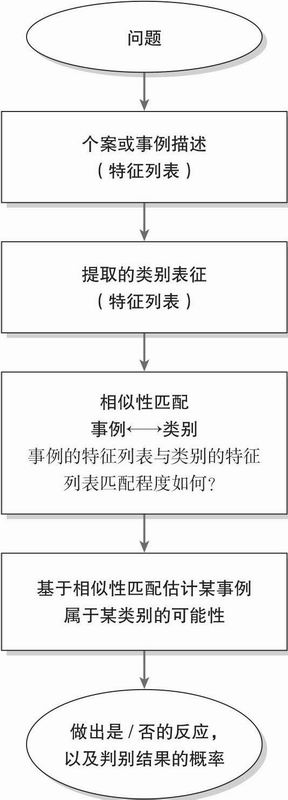
图5.5 代表性启发式的判断流程图
我们讨论分类这一命题时需要用到的最后一个认知理论是相似性判断过程的模型。其中最通行的模型是对比模型,它假设我们在评估某两个或多个实体的相似性时会将它们的属性一一对照(非常快)。该过程的一种有效模型假设我们对相似性的总体印象来自于两实体“匹配”属性数目和“不匹配”属性数目的快速对照表。此模型能够给匹配组和不匹配组赋予权重,以反映我们经验和信念中各属性的重要程度。因此,举个例子来说,如果我们在森林里看到一种生物,它不会飞,并且它体表覆盖皮毛,这两个特征对于我们判断它是“鸟类”的影响力是不同的,后者要强一点。在佩内罗珀的判断情境中,描述的属性与我们刻板印象中艺术史的属性(我们读到此类别的名称时从记忆中提取出来)有太多的“良好匹配”,以至于我们的反应是“艺术史”。在琳达的问题里,对琳达的刻画与由类别标签激活的表征(刻板印象)之间的良好匹配也是女权主义(银行出纳员)多于单纯的银行出纳员。
在许多例子中,一旦某客体被划归为某一类,那么一种基于联想的认知随之被激活。就拿臭鼬来说,这种联想性的认知提供了快速有用的信息:躲开它。但是有时我们基于类别的联想在道德上是令人困扰的,或者直接是非理性的。对后者的研究主要涉及社会刻板印象;我们的“心理资料库”里存储着关于艺术史学生、银行出纳员和瑜伽老师的相对中性的刻板印象,但是也包括一些针对重要社会群体的相对负性的刻板印象。也许最麻烦的就是,这些种族、性别和宗教的刻板印象能自动激活我们的情绪反应,进而影响到针对该类别中具体成员的行为表现。一旦我们将某人归入引起负性联想的范畴中,那么我们会情不自禁地用消极的行为对待他。虽然这不属于本书的讨论范围,但是社会心理学关于刻板反应的研究已经表明,当社会类别被激活或者直接适用到人身上时,我们会做出许多不受控制的演绎或类比推论(Kunda,1999;Wittenbrink & Schwarz,2007)。刻板信念的无意识效应中可能包括反弹效应,即刻板反应在有意削减之后,会在随后的社会交往中发生反弹。
下面描述了大学入学审查委员会的决策过程,为自发的、但是逻辑上可疑的类别联想提供了一个范例。
[布朗大学]入学审查委员会浏览了来自西南部的一所小型农村高中的申请表,旨在寻找被称为“优雅小镇中的孩子”的优秀申请人。埃米在班里名列前茅,英文中等500分,数学和科学上等600分。她家庭贫困,白种人,外地人。她若被录取,将使布朗大学学生的生源地分布更广泛,家庭经济水平更加多样化,可避免使该校成为新英格兰州的研究生预科学校。因此,来自纽约州的申请只有20%会被接收,但是来自七区——俄克拉荷马、德克萨斯、阿肯色州和路易斯安那等州的申请却有40%会被接收。埃米所在的高中对她赞赏有加,她想学习工程学。布朗大学需要学习工程学的学生。但不幸的是,埃米把工程学这个单词拼写错了。语言学教授吉米·雷恩说:“阅读障碍”。争论过后,委员会把她的申请放在了待批行列。
基于代表性思维的决策错在哪里?这又是因为相似性并不总能反映情境中潜在的统计学和因果性结构。拼写错误是阅读障碍的症状,但是拼写不好的人中没有阅读障碍的要比有阅读障碍的多。然而这种图式(拼写错误-阅读障碍)已被存取,埃米被判定为阅读障碍。在做这样的决策时考虑阅读障碍既不切题也不符合伦理,但是本书作者在研究生入学委员会和奖学金分配委员会中却多次观察到类似的情况。
一位申请者在被问及“研究生入学委员会可能看重的其它个人信息”时写道:“身为摩羯座,我将会是一位严谨的实验者。”委员会中一位教授蔑视地说,“我们这儿不需要任何占星术疯子!”。这位在700多人中GRE和GPA综合排名第二的申请人就这样被拒绝了。当然知道自己星座的人中更多的不是“占星术疯子”,但是类别图式(“占星术疯子,因此是不可靠的怪人”)再一次占据上风。
以代表性特征为基础来做判断的基本问题在于,存取的图式实际上比未存取的图式更不合理,特别是当未存取的图式在世界上有更大的覆盖范围时。“非阅读障碍者”和“非怪人”在现实中比“阅读障碍者”和“怪人”占更大的比例。因此,拼写错误的人更可能不是阅读障碍者,知道自己星座的申请者更可能不是怪人。然而,当类别图式通过相似性被自动存取时,它的基准概率则不值一提。那需要一种二级的自我反省式的判断:“这种类型有多普遍?”(阅读障碍者或占星术疯子或艺术史专业)。这样的判断需要忽略描述特征评估基准概率。比如,对佩内罗珀专业“重新考虑”的提醒旨在使读者能够仔细考虑大学生中艺术史和心理学专业的基准概率。漠视情境中的统计学结构和忽略基准概率等关键信息是基于代表性进行判断的行为标志,但是,我们做判断时又该如何恰当地使用基准概率信息呢?
5.10 比例规则
与代表性判断不同,我们可以利用简单的概率论法则进行精确的判断。假设c代表某个特征,S代表某种图式(范畴)。c在多大程度上可以代表S由条件概率p(cS)表示——即S中每个成员具有特征c的概率。(在目前的例子中,该条件概率是挺高的。)
但是,特征c必然指向S成员的概率由条件概率p(Sc)表示,指具有特征c的人属于S中的成员的概率,该条件概率是p(cS)的逆反。现在,由概率论的基本原理可知:

即,c与S同时发生的概率除以S的概率。相似地:

但是,p(c and S)= p(S and c);所以如下所述:

一般而言,

这种关系被叫做比例规则——逆反概率的比率等于简单概率的比率。
在以上讨论推断某个人是否属于某个类别的情境中,这种简单的比例规则能够有效地将p(cS)和p(Sc)联系起来。在p(c)和p(S)不相等的情况下将两个条件概率等同对待是不合理的,但是代表性思维却没有反映出p(cS)与p(Sc)之间的差异,因而表现出现实中不存在的对称性。
由于混淆逆反概率而发生误解的情况有很多,其中广为人知的当属哈佛大学法学教授Alan Dershowitz(他是“辛普森谋杀案”辩护律师“梦之队”成员)的一段电视讲话。他在辩词中没有对辛普森虐待前妻尼克尔的历史做争论。他说,“殴打妻子的男人中只有百分之零点一的人会杀害他们的妻子”(p[丈夫谋杀妻子丈夫殴打妻子])。但是统计学家I.J.Good(1995)寄给科学杂志《自然》的信中指出,相应概率的条件应该是丈夫殴打妻子并妻子随后被谋杀。Good采用Dershowitz的假设计算出了相应概率,结论是在这种情况下1/2的丈夫是杀人凶手:p(丈夫谋杀妻子丈夫殴打妻子并妻子被谋杀)。(实际的简单概率似乎是1/3左右,不过具体的统计数据不详,因为“殴打妻子”这个范畴很难操作化定义。)Good教授还说:“当然,这个观点不仅仅适用于辛普森案件。它再一次戏剧性地表明贝叶斯的简单概念是法律审判的基础。它同样是医学诊断和科学哲学的基础。贝叶斯法则在大学之前就应该掌握!”(p.541)。
关于吸食大麻与严重的药物成瘾之间关系的声明和信念,为上述有关非理性的阐述提供了丰富的证据。例如,1970年12月11日《红木城(加利福尼亚)论坛》上的一篇文章的标题写道:“大部分吸食大麻者还使用其他致瘾药物。”但是接下来的第一句是:“根据研究发现,高中生只要吸食致瘾药物几乎毫无例外地就会吸食大麻。”尽管正文明确表明吸食致瘾药物的学生中大部分都吸食大麻,但是标题却逆转了这种关系。
标题指的是随机选择一个吸食大麻者(M),其吸食致瘾毒品(H)的概率,或者说是“吸食大麻的人中使用致瘾毒品者的概率”。可以用既吸大麻又吸致瘾毒品的人(M and H)的频率除以吸大麻的人(M)的频率得到该概率:
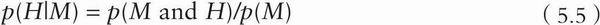
但是所引用的研究指的却是随机选择一个吸食致瘾毒品的人(H),其吸大麻(M)的概率,可以用既吸大麻又吸致瘾毒品的人(M and H)的频率除以吸食致瘾毒品的人的频率得到该概率:

吸食致瘾毒品者中吸大麻的人与吸食大麻者中吸致瘾毒品的人相比,其比率很大,因为吸大麻的人与吸食致瘾毒品的人相比,其比率很大,而这两个比率是相等的(方程5.4)。调查发现前者的条件概率——吸食致瘾毒品中吸大麻的比例——非常高,这也符合我们的日常经验。但是这并不表示逆反概率也非常高。比例规则表明后者的概率——吸食大麻中吸致瘾毒品的比例——比前者要小得多,所以前者值大并不意味着“大部分吸食大麻者[还]使用其它[致瘾]药物。”然而在该研究发表的那个时期,一个民主党总统候选人在竞选前夕的电话问答中把大麻称作“制药行业的讨厌鬼”。
韦恩图(图5.6)再次明确地显示出逆反概率——p(吸大麻吸致瘾毒品)和p(吸致瘾毒品吸大麻)——之间的不同。吸大麻的人并不意味着有很高的可能性吸食其它致瘾毒品,但是吸食致瘾毒品的人意味着有很高的可能性吸食大麻。
在大多数关于逆反混淆(也叫条件概率谬误)的文章中,作者们会给出很滑稽的例子。比如,1967年8月27日《本周》杂志刊登了一篇文章,建议人们如何在交通拥堵的劳动节周末保证生命安全(Barns,1967)。作者声称“驾驶时离家越远越安全”,因为大部分的死亡事故都发生在离家25英里范围内。这是将“距离条件下的死亡概率”与“死亡条件下的距离概率”错误地等同了。通过分析比例规则(方程5.4),我们能很清晰地发现该等同完全是无稽之谈,因为在离家近的地方驾驶的概率要远大于发生死亡事故的概率。这种混淆很容易闹出笑话,一个人如果发生了混淆很可能把车拖到高速公路上之后再自己去开。但是,当同样的非理性被用作正当的借口——甚至有时作为理由——强制对大麻实施严厉的禁令时,混淆便不再仅仅是笑话了。虽然因吸食大麻被逮捕的人可能将逮捕看做政府报复性、保守性和剥削性的自然结果,但是许多人却对逮捕表示赞同,因为他们相信——与已故的Hubert Humphrey一致——大麻是“讨厌鬼”。

图5.6 吸大麻与吸食致瘾毒品之间的逻辑关系韦恩图
偶尔,人们在未考虑任何基准概率(特征[如吸大麻]的发生率,类别[如吸食致瘾毒品]的发生率)的情况下,就断言两种事物之间的相依性以及相依性的方向。请看下面来自《管理聚焦》的例子。
最近一项针对74名CEO的调查发现,童年时期抚养宠物可能与未来的职业成功有关。94%的CEO在小时候都养过狗或猫,而他们现在都受雇于财富500强企业。
被调查者声称,与宠物的相处帮助他们培养了许多积极的品格特质,从而使他们成为今天的优秀管理者。这些特质包括责任心、同理心、对生命的尊重、宽容以及良好的沟通技巧。众所周知,在类似于这些CEO们成长背景下长大的孩子中,有超过94%的人都抚养过宠物,但是此时相关性的方向却可能是负的。也许CEO们的成功与儿童时期刷牙有关。可能所有的CEO都刷牙,至少偶尔刷,然后我们猜测刷牙所需要的自律性导致了他们今天的事业成功。这似乎比童年时与宠物互动而习得的“沟通技巧”能够促进他们与其他经理及雇员的关系要更加合理些。
心理学家也不可避免地会做出这种错误判断。例如,Nathan Branden(1984)写道:“我想不出来有哪个心理问题不是起源于低自尊的——从焦虑、抑郁到亲密恐惧或成功恐惧,到酒精或药物滥用,到配偶虐待或狎童。”换句话说,c代表低自尊而S代表心理问题,p(cS)是高的。但是说这些心理问题的根源在于低自尊即是声称p(Sc)高,而这点我们并不清楚——来访者之所以来咨询Branden,是因为他们已经有了心理问题。Branden的经验仅限于那些因心理问题而想寻求帮助的人——他的经验是以S作为条件的。即使我们真地发现了高概率的p(Sc),我们也不能做出因果推论:人们的自尊也许是因为身患心理疾病才变低的。Branden的总结如下:
大量证据(包括一些科学研究发现)表明,个体的自尊水平越高,对待他人时就会越尊重、越友善、越宽容。没有体验过自爱的人是没有能力去爱别人的。体验过深层不安全感和自我怀疑的人,倾向于把其他人知觉成可怕的和敌意的。没有自尊的人无法对这个世界做出任何贡献。
套用Branden(1984)的“我想不出来”的句型,我们想不出来有哪个科学研究中的因变量是“无法对这个世界做出任何贡献”的。有心理问题的人(Branden的案例中)有低水平的自我意象,但这并不意味着“深层不安全感和自我怀疑”(不常见的特征)条件下出现心理问题的概率就一定高。“深层”这个词模糊性太强,以致于无法用清晰的统计来反驳Branden命题的不可能性,但是,使用代表性思维同一群“无法对这个世界做出任何贡献”的人交流在理智上是不负责任的行为。事实上,Branden的观察能够证明一点,低自尊对于这些有心理问题(如虐待儿童)的人来说是好现象,否则他们也不会去寻求改变(如接受治疗)。
庆幸的是,并不是所有人在任何时候都将逆反条件概率弄混淆,比如伟大的哲学家伯特兰·罗素就不会这样。他的祖母曾不遗余力地劝他别跟他的第一任妻子结婚,这让他深刻地意识到他们家的精神病人何其之多。九年后,当他考虑要孩子时向医生咨询了精神病的遗传情况。他的传记作家Clark(1976)是这样描述的:
四天后他见了医生,“医生说冒险受孕需要承担起责任,人们对遗传的恐惧被夸大了。他说50%的精神病患者的双亲酗酒,但是只有15%的精神病患者的双亲也是精神病。这似乎使我稍稍心安。”也就是说,直到罗素这位准父亲成为统计学家罗素时才能稍稍心安。他在日记下方的脚注中写道:“但是,他没有特别指出总人群中患精神病者和酗酒者的比例分别有多大,所以他的论点没有一点价值。”
在这个例子中,即使是罗素也能被挑出“没头脑”的毛病。比如,为何他刚开始时那么严肃认真地看待50%和15%呢?问题在于想避免发生混淆,就有必要把很少经历过的客体或事件也假设成一类——比如,低自尊却仍然有能力爱别人或“能对世界做出些贡献”的人。然后,要想估计出条件概率值,则必须估计这类罕见事件的囊括范围,尽管我们很少接触到这类人或事。这需要控制性的“科学”思维——用皮亚杰的术语来说是,把真实(已经观察到的)看做可能(可能被观察到的),而不是反过来。
当我们直接体验各种事件而不是阅读书面材料时,即使不是伟大的哲学家,普通人也能恰当地利用基准概率信息。当研究对象是在职的医生和会计时,他们似乎能意识到相应的基准概率,例如当地疾病的发生率或财务问题的发生率。虽然这能使人稍微放心一些,但是在嘈杂的日常情境中仍然有某些忽略基准概率的情况存在。模拟医疗诊断的实验室研究发现,给参与者呈现基准概率不同的病例之后(如,25%的情况演变成疾病burlosis,75%的情况演变成疾病coragia——疾病burlosis和coragia均为虚构),他们对基准概率反应敏感,但是在某些实验条件下仍存在着对基准概率的忽略(Gluck & Bower,1988;Goodie & Fantino,1995,1996)。
还有一种情况能让我们重视基准概率,即人们给不一致的比率赋予某种因果性意义时。当人们能够看出基准概率的因果关联时,他们经常把基准概率纳入推理过程中。例如,若模拟陪审员相信一家公交公司比另一家公交公司发生更多的交通事故是由于他们的司机没有经过严格的筛选和培训,那么他在评估目击者证词时会将不同的事故发生率考虑在内。但是,若他认为一家公交公司交通事故多仅仅是因为公司比较大,那么他将不会考虑不同的事故发生率。研究反复证实,当基准概率只具有统计学意义而缺乏因果性意义时,它们通常会被忽略。相同的效应似乎在真实的法庭上也出现过,赤裸裸的统计学证据非常没有说服力——比如,在指控辛普森杀害妻子及其男友的案件中,DNA证据无法说服陪审团定罪。当然,比例规则的等式右边为什么碰巧是p(A)和p(B),这个问题也很重要,理性应有其用武之地(Koehler,1997)。但是因果思维有自身的陷阱,这点我们将在下一章讨论。
总之,我们似乎更擅长将潜在关系用具体数字和具体频率表示出来,而不是将潜在关系用抽象的比例和概率表示(见最近的综述文章,Barbey & Sloman,2007)。我们将在第8章重新回到这个问题上并且给出一些正确建议,以便于处理条件概率关系。
在大部分时间里,我们的绝大多数思考被无处不在的思维和联想规则掌控,因而我们会做出代表性联结,特别是在评估概率时。本章关注了非正式的观察和理论。此外,研究者也做过大量关于代表性思维的实证研究(通常用大学生作为被试),结果都证实了相似性和联想的主导作用。幼稚天真的被试们在许多情境下对 p(AB)和p(BA)不加区分,而且当给出一个条件概率时,他们直接推断出另一个概率而并不参考p(A)和p(B)的基准概率,这明显违反了比例规则。我们具有一种很自然的习惯,即用联想的方式来思考当下情境中凸显的事物或者第一时间从记忆中提取到的事物。要想逃离这种“被现成性所主导”并思考那些经验中并不明显的事物和关系时,意志力和训练必不可少。
参考文献
Alvarez, L.W.(1965, June 18).A pseudo experience in parapsychology.Science, 148(3677), 1541.
Barbey, A.K., & Sloman, S.A.(2007).Base-rate respect: From ecological rationality to dual processes.Brain and Behavioral Sciences, 30, 241-297.
Barns, L.R.(1967, August 27).This quiz could save your life next weekend.This Week, 10-11.
Birnbaum,M.H.(1983).Base rates in Bayesian inference: Signal detection analysis of the cab problem.American Journal of Psychology, 96, 85-94.
Branden, N.(1984, August/September).In defense of self.Association for Humanistic Psychology Perspectives, 12-13.
Clark, R.W.(1976).The life of Bertrand Russell.New York: Knopf.
Combs, B., & Slovic, P.(1979).Newspaper coverage of causes of death.Journalism Quarterly, 56, 837-843.
Diaconis, P., & Mosteller, F.(1989).Methods for studying coincidences.Journal of the American Statistical Association, 84, 853-861.
Douglas, M., & Wildavsky, A.(1982).Risk and culture: An essay on the selection of technical and cultural dangers.Berkeley: University of California Press.
Gigerenzer, G.(2006).Out of the frying pan into the ire: Behavioral reactions to terrorist attacks.Risk Analysis, 26, 347-351.
Gilliam, F.D., Jr., Iyengar, S., Simon, A., & Wright, O.(1996).Crime in black and white: The violent, scary world of local news.Harvard International Journal of Press/Politics, 1, 6-23.
Glassner, B.(1999).The culture of fear: Why Americans are afraid of the wrong things.New York: Basic Books.
Gluck, M.A., & Bower, G.H.(1988).From conditioning to category learning: An adaptive network model.Journal of Experimental Psychology: General, 117, 227-247.
Good, I.J.(1995).When batterer turns murderer.Nature, 375, 541.
Goodie, A., & Fantino, E.(1995).An experientially derived base-rate error in humans.Psychological Science, 6, 101-106.
Goodie, A., & Fantino, E.(1996).Learning to commit or avoid the base-rate error.Nature, 380, 247-249.
Goodman, G.S., Qin, J., Bottoms, B.L., & Shaver, P.R.(1994).Characteristics and sources of allegations of ritualistic child abuse.Washington, DC: National Resource Center on Child Abuse and Neglect.
Gould, S.J.(1991).Bully for brontosaurus: Relections in natural history.New York: Norton.
Hopkins, B., & Jacobs, D.M.(1992).How this survey was designed.In B.Hopkins, D.M.Jacobs, R.Westrum, J.E.Mack, J.S.Carpenter, & Roper Organization, Unusual personal experiences: Analysis of the data from three major surveys conducted by the Roper Organization (pp.55-58).Las Vegas, NV: Bigelow Holding Company.
Johnson, E.J., & Tversky, A.(1983).Affect, generalization, and the perception of risk.Journal of Personality and Social Psychology, 45(1), 20-31.
Kahneman, D.(2003).A perspective on judgment and choice: Mapping bounded rationality.American Psychologist, 58, 697-720.
Kingdon, J.W.(1984).Agendas, alternatives, and public policies.Boston: HarperCollins.
Koehler, J.J.(1996).The base-rate fallacy reconsidered: Descriptive, normative, and methodological challenges.Brain and Behavioral Sciences, 19, 1-53.
Koehler, J.J.(1997).One in millions, billions, and trillions: Lessons fromPeople v.Collins (1968) for People v.Simpson (1995).Journal of Legal Education, 47, 214-223.
Kunda, Z.(1999).Social cognition: Making sense of people.Cambridge: MIT Press.
Macchi, L., Osherson, D., & Krantz, D.H.(1999).A note on superadditive probability judgment.Psychological Review, 106, 210-214.
Mulford, M., & Dawes, R.M.(1999).Subadditivity in memory for personal events.Psychological Science, 10, 47-51.
Nathan, D., & Snedeker, M.(1995).Satan-s silence.New York: Basic Books.
Nisbett, R.E., & Ross, L.(1980).Human inference: Strategies and shortcomings of social judgment.Englewood Cliffs, NJ: Prentice Hall.
Park, J., & Banaji, M.R.(2000).Mood and heuristics: The inluence of happy and sad states on sensitivity and bias in stereotyping.Journal of Personality and Social Psychology, 78, 1005-1023.
Pinker, S.(1997).How the mind works.New York: Norton.
Redelmeier, D.A., Koehler, D.J., Liberman, V., & Tversky, A.(1995).Probability judgment in medicine: Discounting unspeciied possibilities.Medical Decision Making, 15, 227-230.
Reyes, R.M., Thompson,W.C., & Bower, G.H.(1980).Judgmental biases resulting from differing availabilities of arguments.Journal of Personality and Social Psychology, 39, 2-12.
Ross, M., & Sicoly, F.(1979).Egocentric biases in availability and attribution.Journal of Personality and Social Psychology, 37, 322-336.
Rottenstreich, Y., & Tversky, A.(1997).Unpacking, repacking, and anchoring: Advances in support theory.Psychological Review, 104, 406-415.
Sartre, J.P.(1948).Anti-semite and Jew (G.F.Becker, Trans.).NewYork: Schocken Books.
Schwarz, N.(2004).Metacognitive experiences in consumer judgment and decision making.Journal of Consumer Psychology, 14, 332-348.
Schwarz, N., Bless, H., Strack, F., Klumpp, G., Rittenauer-Schatka, H., & Simons, A.(1991).Retrieval as information: Another look at the availability heuristic.Journal of Personality and Social Psychology, 61, 195-202.
Tversky, A., & Kahneman, D.(1974).Judgment under uncertainty: Heuristics and biases.Science, 185, 1124-1131.
Tversky, A., & Kahneman, D.(1983).Extensional versus intuitive reasoning: The conjunction fallacy in probability judgment.Psychological Review, 90, 293-315.
Tversky, A., & Koehler, D.J.(1994).Support theory: A nonextensional representation of subjective probability.Psychological Review, 101, 547-567.
Wittenbrink, B., & Schwarz, N.(2007).Implicit measures of attitudes: Procedures and controversies.New York: Guilford Press.
Wright,W.F., & Bower, G.H.(1992).Mood effects on subjective probability assessment.Organizational Behavior and Human Decision Processes, 52(2), 276-291.